
안녕하세요. 와디즈 회원개발팀입니다.
작년 메인 개편과 함께 앱 내 소셜 커뮤니티인 ‘피드’ 서비스를 런칭했어요. 올 상반기에는 이 서비스를 ‘친구’ 서비스로 변경 및 개선을 진행했습니다.
의미 있는 친구를 사용자에게 추천하기 위한 다양한 작업을 했는데요. 그 과정에서 그래프 DB(Graph Database, 그래프 데이터베이스 이하 그래프 DB)를 활용했어요. 도입 과정에서 있었던 내용들을 소개합니다.

개발 배경
‘친구’ 서비스 개선에서 받은 요구사항은 아래와 같았어요.
- 내가 팔로우한 ‘친구의 친구‘를 추천해 줘야 한다.
- 조회 당사자와 이미 팔로우했거나 차단한 인원은 제외되어야 한다.
- ‘친구의 친구‘는 각각 몇 명의 친구가 팔로우하고 있는지와 대표가 되는 친구 한 명을 알려줘야 한다.
- ‘친구의 친구‘와 내가 공통으로 팔로우하는 친구의 수를 알려줘야 한다.

요구사항을 구현했을 때 모습
왜 Graph DB인가
요구사항만 분석했을 때, 우리가 많이 사용하는 RDB(Relational Database, 관계형 데이터베이스 이하 RDB)에서도 복잡하기는 하지만 쿼리로 풀어내는 게 어렵진 않아요. 하지만 우린 그래프 DB를 선택했죠. 왜일까요?
우리가 기대하는 서비스의 성능은 어떤 데이터베이스를 사용하든지 어떻게 인프라 사양을 준비할지, 어떻게 데이터베이스의 설정을 튜닝할지, 어떻게 모델을 설계하고 어떤 형태로 서비스에서 쿼리를 요청할지 등, 요소에 따라 영향을 받습니다. 그래서 성능 좋은 서비스를 만들기 위해서는 각 구간에서 좋은 설계를 고민하고 어떤 제품을 사용할지 선택을 잘해야 해요. 그런데 만약, 기대하는 데이터의 형태가 명확하다면 데이터베이스 선택에서부터 특정한 선택을 가져갈 수 있습니다.
‘친구의 친구’를 찾는 데이터의 형태는 단순 조회를 넘어 ‘관계’를 중심으로 데이터들을 조회해야 합니다.
*’관계형’과 우리가 앞으로 그래프 DB에서 다룰 ‘관계’와는 미묘한 차이가 있어요. ‘관계형’의 관계는 RDBMS의 아키텍처의 근간이 되는 ‘관계대수’라는 수학 용어에서 비롯되었는데요. 그래서 ‘관계형’이라는 표현은 일반적인 개념과는 다르게 해석됩니다.
‘관계’를 기반으로 데이터를 좀 더 세밀하게 조회할 수 있어야 하므로 컬럼 기반의 참조키 형태를 가지는 RDB만으로는 한계가 있어요. 개편 요구사항의 경우 ‘관계’ 기반의 모델링이 가능하기 때문에 ‘관계’에 특화되어 아키텍처가 설계된 그래프 DB로 좀 더 안정적인 서비스를 설계할 수 있겠다고 생각했습니다.
그래프 DB가 ‘관계’에 적합한 이유를 설명하기 위해서 그래프에 대한 개발자와 비개발자의 인식 차이를 설명해 드릴게요.

(좌) 일반 그래프 / (우) 쾨니히스베르크의 다리 (출처: Leonhard Euler, Solutio Problematis ad Geometriam Situs Pertinentis)
* 쾨니히스베르크의 다리: 오일러가 마을의 지도로부터 그래프를 추상화해서 한붓그리기에 대한 증명을 한 다리.
우리가 흔히 알고 있는 그래프를 봅시다. 특정 값에 의해 정의된 점과 선으로 데이터가 표현된다면, 그래프라고 할 수 있어요. 개발자 시각에서는 그래프 점들의 관계로부터 다양한 경로를 찾을 수 있고 추상화할 수 있다면, 그 모든 형태를 그래프라고 할 수 있어요. 그 모양이 마치 쾨니히스베르크의 다리 같아요.
그래프 DB에서 다루게 될 데이터가 점과 선으로 표현할 수 있고, 그 관계로부터 의미 있는 데이터를 만들어 낼 수 있다면 적합한 데이터다 말할 수 있어요. 친구 서비스에 적용하면, 친구를 포함한 사용자를 점으로, 팔로우 및 팔로우의 방향을 선으로 그래프를 추상화할 수 있습니다. 그래프 DB는 그래프 데이터를 모델링하고 조회하기 좋게 설계된 데이터베이스라고 말할 수 있어요.
그래프 DB 선정 과정
그래프 DB가 일면 생소해 보이지만 생각보다 꽤 많은 제품이 있습니다. 우리가 선택한 건 Neo4j예요.
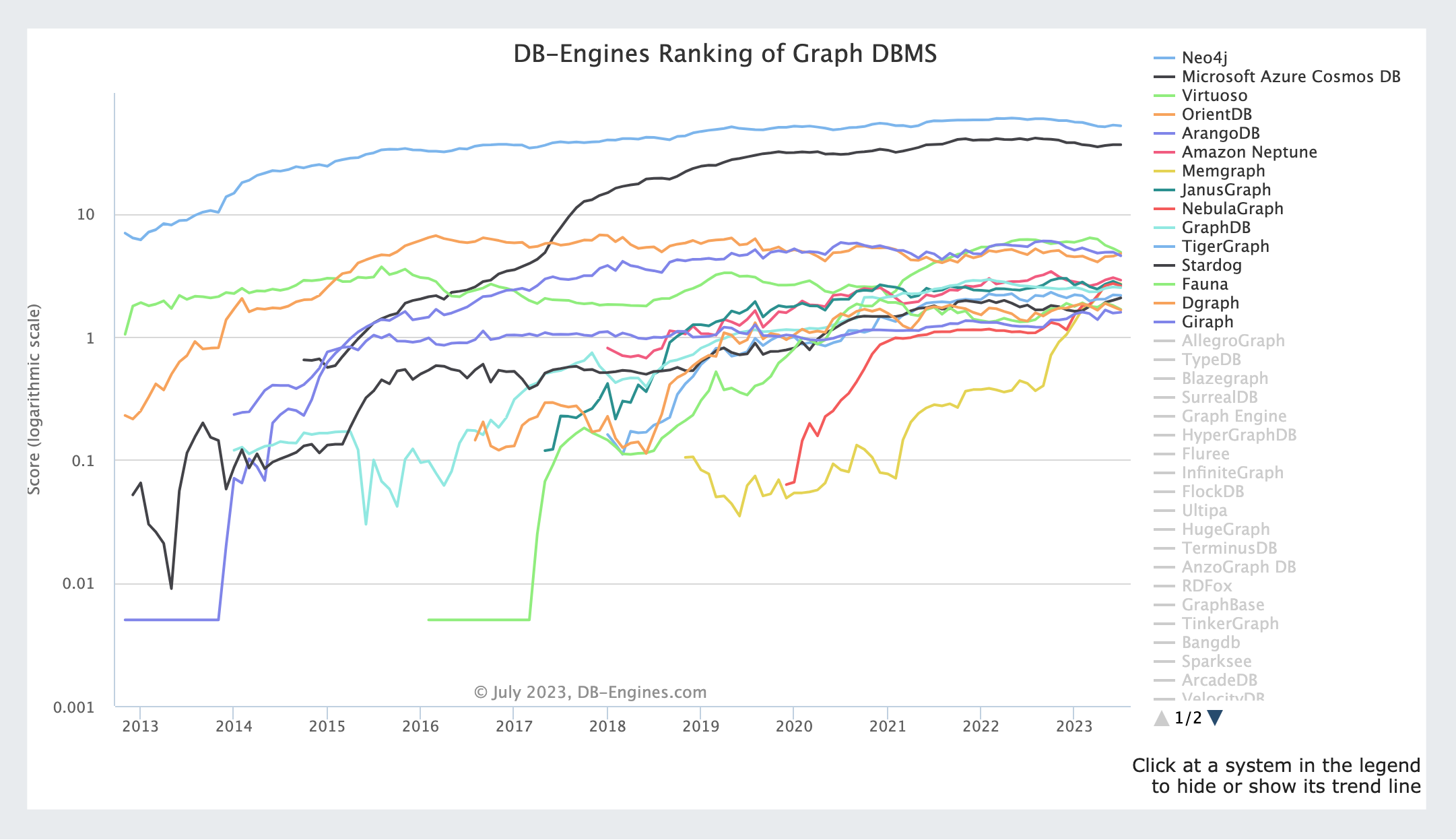
현재 랭킹 1위 제품! 랭킹이 제품이 뛰어남을 평가한 것은 아니지만요😅 / DB-Engines Ranking of Graph DBMS
아래 기준으로 어떤 제품을 선택할 지 살펴봤습니다.
- 믿을만한 제품인가?
- 레퍼런스가 많은가?
- 접근성이 좋은가?
- 러닝커브가 적당한가?
- 비용은 적당한가?
- 인프라 확장에 용이한가?
1~3번은 위 랭킹의 순위 차이만으로 어느 정도 파악할 수 있었어요. 랭킹은 인기순에 가까워요. 순위는 많이 사용되고 있고, 사람들이 제품에 많은 관심을 가지고 활동하고 있다는 것을 알려줍니다. 그만큼 안정성도 보장되고, 레퍼런스도 많으며, 접근성도 좋다고 생각했어요.
어느 그래프 DB를 선택하든 러닝커브는 동일하다고 생각되었고(4번), Neo4j은 Community 버전을 사용할 수 있다 보니 아키텍처 구성 및 상황에 따라 좋은 선택지가 될 수도 있겠다고 생각했어요. (5번)
인프라 확장의 측면에서는 클라우드 제품인 MS Cosmos DB나 AWS Neptune도 좋은 선택지로 보였어요. 하지만 Neo4j도 클라우드 제품을 구비하고 있고 엔터프라이즈 버전의 경우 클러스터링이 가능하기 때문에 Neo4j가 적합하다고 판단했습니다.
개발 과정
Neo4j Desktop
Neo4j는 ‘Neo4j Desktop’이라는 Tool을 제공하고 있습니다.

Neo4j Desktop을 설치한 후 실행한 모습, 설치 경로: Download Neo4j Desktop
‘Neo4j Desktop’은 로컬 환경에 쉽게 Neo4j를 설치해서 테스트할 수 있어요. 실제 서버에 구동되고 있는 Neo4j에도 원격 접속 기능을 제공하고 있어서 로컬과 동일한 환경에서 테스트할 수 있다는 장점도 가지고 있습니다. 쿼리의 결과물을 그래프 형태로 출력할 수도 있어서 그래프 형태의 데이터를 파악하기에도 좋아요.

데이터를 그래프 형태로 볼 수 있습니다.
RDB에 SQL(Structured Query Language)이 있다면 그래프 DB에는 GQL*(Graph Query Language)이 있어요.
*검색 시 GraphQL과 혼선이 있을 수 있어요. 동일하게 GQL 이라는 축약어를 사용하고 있습니다.
다양한 GQL중, Neo4j는 ‘Cypher’를 사용하는데요. Neo4j가 만들어서 공개했지만, 이후 ‘openCypher‘로 개방도 하면서 여러 벤더사에서도 지원하는 GQL입니다.
기본 문법에 대해서 간단하게 설명해 드릴게요. Cypher는 Node/Relationship*으로 데이터 생성 및 관리합니다. 주요 Feature는 아래와 같아요.
*그래프 알고리즘에서는 보통 vertex/edge라고 표현하지만, cypher에서는 node/relationship이라고 합니다.
- Node는 ‘Label’을 달아서 구분하고 각 Node 인스턴스는 ‘Property’를 추가해서 데이터를 저장합니다.
- Relationship은 ‘Type’을 가지고 있는데 ‘Label’과 구분되며 단일 ‘Type’만 가질 수 있습니다. (’Label’의 경우 하나의 Node가 여러 개의 ‘Label’을 가질 수 있습니다.)
- Relationship도 ‘Property’를 추가해서 데이터를 저장합니다.
- Neo4j는 NoSQL로 Schema free라서 ‘Property’에 대한 제약이 적습니다. (동적으로 추가할 수 있고 동일 Property에 대한 data type의 제약이 없습니다.)

간단하게 쿼리 예시를 들어볼게요. 쿼리 내용과 결과입니다.
Node 생성
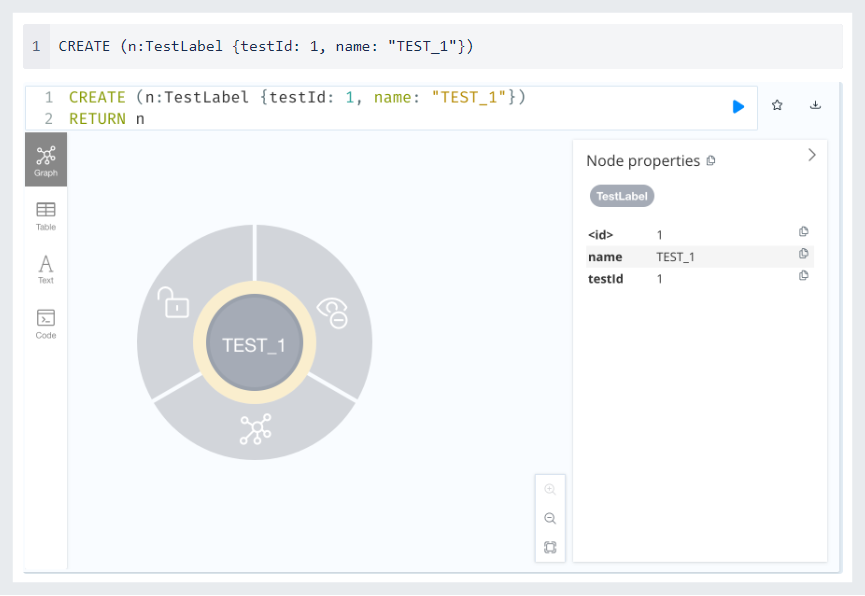
Relationship 생성

조회
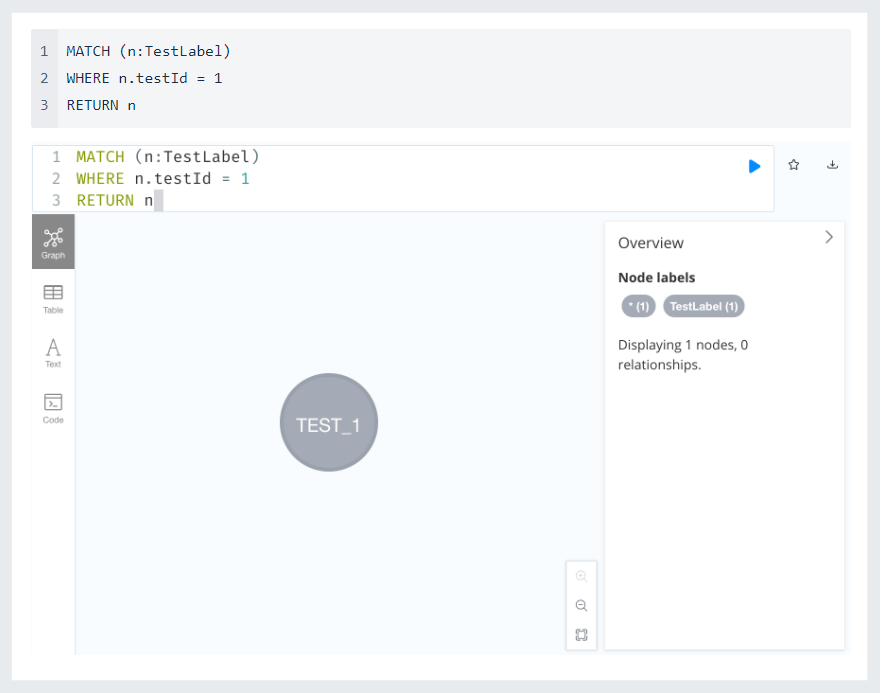
업데이트

삭제 : 일반 삭제

삭제 : Relationship을 포함한 삭제

그래프 데이터 모델링
실제 개발은 ‘Neo4j Desktop’에 ‘Cypher’로 테스트하면서 이뤄지는데요. 그래프 DB를 활용한 개발 과정에서 제일 중요한 부분은 모델링입니다.
데이터들이 그래프 형태로 구체화되어야 활용도도 높아져요. 실제 그래프 DB에 조회 시 그래프 패턴을 가지는 모델링이 선행되어야 좋은 성능을 낼 수 있습니다. 그래서 그래프 데이터 모델링은 중요한 작업 중 하나예요.
모델링 예를 들어볼게요. A라는 사람이 B라는 사람에게 100달러를 ‘와디즈 은행’으로 ‘2023-07-09 14:00:00’에 이체한 이력을 모델링한다고 해보겠습니다.
CREATE (a1:Account {name: 'A'})-[:TRANSFER {
id: 555,
amount: 100,
currency: 'USD',
bank: 'Wadiz',
date_time: '2023-07-09 14:00:00'
}]->(a2:Account {name: 'B'})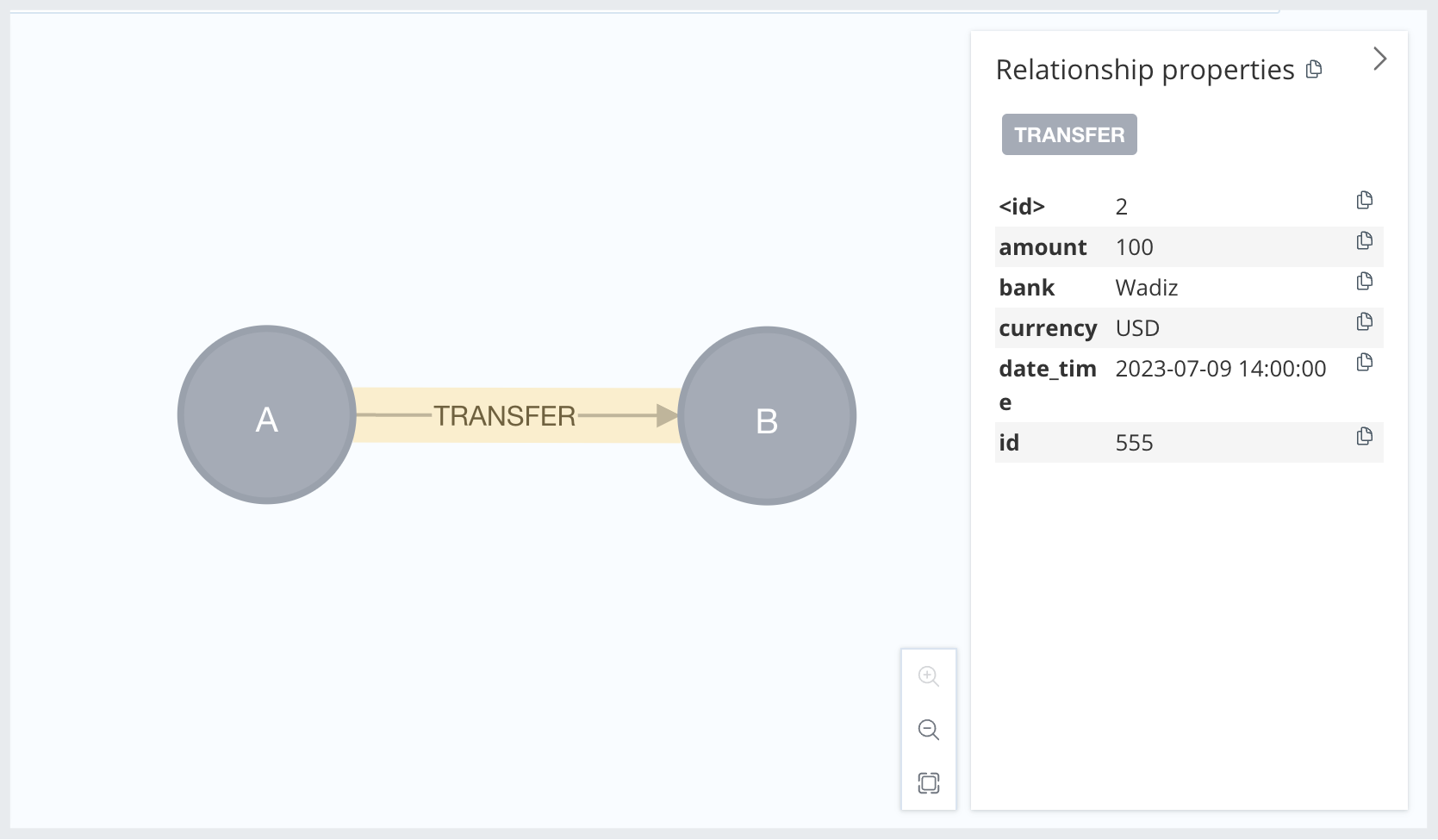
굉장히 직관적인 모델링입니다. 어떤가요? 낯설기는 하지만 잘못된 것은 아니라 생각이 돼요. Neo4j 아키텍트 중에 한 사람인 ‘David Allen’은 해당 모델링에 대해서 ‘Very bad‘라고 이야기 하는데요. 왜 그렇게 생각할까요? 다른 모델링을 한번 보겠습니다.
CREATE (bk:Bank { name: "Wadiz" })
CREATE (c:Currency { name: "USD" })
CREATE (a:Account {name: 'A'})-[:INITIATES]->
(bt:BankTransfer { id: 555, amount: 100, date_time: '2023-07-09 14:00:00' })
-[:RECEIVES]->(b:Account {name: 'B'})
CREATE (b)-[:ORIGIN_BANK]->(bk)
CREATE (b)-[:CURRENCY]->(c)
첫 번째 모델링에서 비해 어떤가요? 더 복잡하고 어려워 보이나요? ‘David Allen’은 위 모델링을 ‘Much better‘라고 표현합니다.
첫 번째 모델링은 RDB 모델링에 가깝습니다. ‘Account’ table과 ‘Account’ 간에 관계를 Mapping한 ‘Transfer’ table의 row 사이의 관계를 도식화한 느낌에 가까워요.
두 번째 모델링의 경우 데이터 내부의 데이터들을 분리하고 각 데이터 간의 ‘관계’들을 세분화하면서 ‘관계’ 기반의 데이터 확장성과 다양한 관계들을 표현해 주고 있어요.
그래프 내부에서 데이터를 찾는 기반은 결국 ‘관계’이기 때문에 이런 모델링은 다양한 조회를 할 수 있는 기반을 제공해 줍니다. (Cypher에 대한 깊이 있는 이해를 바탕으로 한 쿼리 튜닝만으로는 성능을 끌어내는데 한계가 있어요. 기본적으로 모델링이 성능을 내기 위한 기반을 받쳐주지 않으면 쿼리를 잘 작성하기도 어렵고 성능을 기대하기도 어려워요.)
따라서, 실제 작업 시 모델링에 굉장히 많은 에너지를 쏟아야 했어요. 원본 데이터인 RDB를 기준으로 데이터 파이프라인을 구성한 후, 그래프 DB 모델링과 그 모델링을 기반으로 쿼리를 작성하고 테스트했습니다. (모델링에 대해서는 전해드리고 싶은 말은 더 많지만, ‘David Allen’이 기고한 글을 읽어보시기를 추천드려요.)
SQL vs Cypher
처음으로 돌아가 요구사항을 다시 생각해 봅시다. 요구사항을 현재 RDB를 기준으로 SQL을 작성해 보고, Cypher로 작성했을 때, 쿼리의 내용, 성능과 비교해 볼게요.
*완전히 동일한 환경은 아니지만, 8Core 16G는 동일한 상황이며, LIMIT 없이 첫 로딩 실행시간만 비교해 보도록 하겠습니다.
<테스트 대상의 데이터>
- ‘친구’ 수 : 1,300여 명
- ‘친구의 친구’ 수 : 8천 명(중복포함 : 12만 명)
SQL
* 이해를 돕기 위해 실제 테이블/컬럼명이 아닌 의사코드 형태로 표현하였습니다.
SELECT *
# '친구의 친구'와 공통 팔로워 수
,(SELECT count(f1.<팔로워_USER_ID>) as cnt
FROM [팔로우_테이블] f1
INNER JOIN [팔로우_테이블] fx ON (f1.<팔로우_타겟_USER_ID> = fx.<팔로우_타겟_USER_ID> AND fx.<팔로우_여부> is true)
INNER JOIN [USER 테이블] u on u.<USER_ID> = f1.<팔로우_타겟_USER_ID>
WHERE f1.<팔로워_USER_ID> = <##조회_대상_USER##>
AND fx.<팔로워_USER_ID> = follow_of_follow.fx
AND f1.<팔로우_여부> is true
) AS common_follow_count
FROM (SELECT GROUP_CONCAT('(', f1.<팔로우_타겟_USER_ID>, ',', u1.<USER_NAME>, ')') as f1_list, f1.<팔로우_타겟_USER_ID> as rep_f1_user_id, u1.<USER_NAME> as rep_f1_user_name,
count(f1.<팔로우_타겟_USER_ID>) as f1_count, fx.<팔로우_타겟_USER_ID> as fx, u2.<USER_NAME> as fx_name
# 1차 팔로우 조건: 팔로우가 ON된 정상 User
FROM (SELECT <팔로워_USER_ID>, <팔로우_타겟_USER_ID>, <팔로우_여부> FROM [팔로우_테이블] f
INNER JOIN [USER 테이블] u on u.<USER_ID> = f.<팔로우_타겟_USER_ID>이
WHERE <팔로워_USER_ID> = <##조회_대상_USER##> AND <팔로우_여부> is true) f1
# '친구', '친구의 친구' User 정보 Join
INNER JOIN [팔로우_테이블] fx ON fx.<팔로워_USER_ID> = f1.<팔로우_타겟_USER_ID> AND f1.<팔로우_여부> is true AND fx.<팔로우_여부> is true
INNER JOIN [USER 테이블] u1 ON f1.<팔로우_타겟_USER_ID> = u1.<USER_ID>
INNER JOIN [USER 테이블] u2 ON fx.<팔로우_타겟_USER_ID> = u2.<USER_ID>
# '친구의 친구' 중 조회자 제외, 이미 '친구'인 경우 제외, 차단한 경우 제외
WHERE fx.<팔로우_타겟_USER_ID> != <##조회_대상_USER##>
AND fx.<팔로우_타겟_USER_ID> NOT IN (SELECT <팔로워_USER_ID> FROM [팔로우_테이블] WHERE <팔로워_USER_ID> = <##조회_대상_USER##> AND <팔로우_여부> is true)
AND fx.<팔로우_타겟_USER_ID> NOT IN (SELECT <차단_USER> FROM [차단_테이블] WHERE <USER_ID> = <##조회_대상_USER##> AND <팔로우_여부> is true)
GROUP BY fx.<팔로우_타겟_USER_ID>
) follow_of_follow
// '친구'가 많이 팔로우 하는 순으로 정렬
ORDER BY follow_of_follow.f1_count DESCCypher
CALL {
// '친구의 친구' 조회
MATCH (n:User {user_id: <##조회_대상_USER_ID##>})-[r1:FOLLOW]->(f1:User)-[r2:FOLLOW]->(fx:User)
// 이미 '친구' User, 차단한 User, 조회 당사자 제외
WHERE NOT ((n)-[:FOLLOW]->(fx)) AND NOT ((n)-[:BLOCK]->(fx)) AND n <> fx
// '친구의 친구' 정보
RETURN n, fx, fx.user_id as target_id, fx.user_name as target_name,
count(fx.user_Id) as target_count, collect(distinct f1) as f1_list
// '친구'가 많이 팔로우 하는 순으로 정렬
ORDER BY target_count DESC
}
CALL {
// '친구의 친구'와 공통 팔로워 수
WITH n, fx
MATCH (n)-[:FOLLOW]->(c:User)<-[:FOLLOW]-(fx)
RETURN count(c) as common_follow_count
}
WITH target_id, target_name, target_count, f1_list, common_follow_count
// '친구의 친구'의 기본 정보
RETURN target_id, target_name, target_count,
// '친구의 친구'를 찾는데 사용된 '친구' 기본 정보
f1_list[0].user_id as weight_rep_user_id, f1_list[0].user_name as weight_rep_username, size(f1_list) as weight_count,
// '친구의 친구'와 공통 팔로워 수
common_follow_count결과
<첫 실행 시간>
- SQL : 37.73 초
- Cypher : 2.27초
우선 쿼리 내용을 보도록 하겠습니다. 어떤가요? 어떤 쿼리가 가독성이 더 좋나요? Cypher를 잘 알지 못해도 Cypher가 가독성이 더 좋고 이해하기 쉬운 형태인 것은 누구나 알 수 있습니다.
성능은 어떨까요? 물론 양쪽 다 내부 Cache를 사용하기 때문에 첫 실행 이후에는 크게 문제가 없어요. 하지만 해당 Cache는 조회 대상자가 바뀌면 거의 의미가 없기 때문에 RDB에 그래프 패턴의 데이터 조회를 한다는 것은 매우 위험하다는 것을 알 수 있습니다.
Cypher도 물리적인 데이터양이 많은 경우 이에 따라 발생하는 일부 Latency 자체는 피할 수는 없어요. 실제 서비스에서는 다양한 전략들을 적용하여 서비스하고 있습니다.
서비스 적용
‘친구’ 서비스는 무엇이 달라졌나
‘친구’ 서비스는 ‘친구의 친구’를 ‘내가 알 수도 있는 서포터’라는 이름으로 제공하고 있어요. ‘최근 활동한 친구’의 콘텐츠도 보여주고 있는데요. 이 또한 그래프 DB를 통해 해결하고 있습니다. ‘최근 활동한 친구’의 경우 ‘친구의 친구’보다 무거운 요구사항을 가지고 있어요. 그 내용은 아래와 같습니다.
- 최근 특정 기간 내 ‘지지서명’, ‘체험리뷰’, ‘만족도 리뷰’ 등의 다양한 활동을 기반으로 한 추천 대상 사용자를 찾는다.
- 해당 사용자 중에서 ‘친구의 친구’를 우선 찾는다.
- 해당 사용자 중에 ‘나를 팔로우 하는 친구’를 찾는다.
- 추가로 다양한 방법으로 사용자를 추천한다.
- 본인 및 본인과 부정적 관계인 사용자는 제외되어야 한다.
‘친구의 친구’보다 해당 내용은 많은 데이터를 활용해야 했어요. 모델링이 보다 더 중요하고 주요했던 요구사항이었죠. 보다 전략적인 모델링을 설계해야 했는데 다음에 기회가 되면 다시 한번 소개해 드릴게요.
그래프 DB를 활용한 ‘친구’ 서비스는 최초 ‘친구의 친구’를 적용하여 와디즈 안에서 나와 친밀한 관계를 맺고 있는 ‘친구’들을 추천 받을 수 있었어요. 이후 ‘최근 활동한 친구’를 통해 나에게 의미 있는 다양한 ‘친구’들의 따끈따끈한 소식까지 받아볼 수 있게 되었습니다.

최근 1달간 서비스 모니터링

보라색 선: 친구의 친구, 파란색 선: 최근 활동한 친구
최근 1달간 서비스에 반영된 평균 응답 Latency입니다. 평균적으로 100ms 이내의 성능을 보여주고 있어요. 많은 데이터를 기반으로 한 관계 데이터임에도 해당 API의 경우에는 속도 저하 없이 빠르게 대응할 수 있었습니다.
마치며
새로운 기술을 도입한다는 것은 언제나 부담이에요. 그러나 도전하지 않고, 실행해 보지 않으면서 급변하는 물살에 올라타기란 쉽지 않다고 생각합니다.
이번 그래프 DB 도입 과정에서 와디즈 회원개발팀은 단순 그래프 DB만 활용하지 않았어요. 와디즈에서 새롭게 시도하는 다양한 기술을 적용해 실제 서비스에 반영했습니다. 앞으로 만들어질 새로운 서비스에 의미 있는 이정표가 되지 않았나 싶어요.
도전은 저 혼자 힘으로 이루어지지 않았어요. 설계부터 구축까지 함께 해주신 여러 동료가 있었기 때문에 마침표를 찍을 수 있었어요. 서로의 필요를 채워주는 동료, 진국이분들이 있기에 다음 도전도 기대됩니다. 감사합니다 🙂
함께 하고 싶다면? 👀
현재 채용 중인 개발 직군 보러가기 👉 클릭



