
안녕하세요! 와디즈 펀딩개발팀 소속, 백엔드 개발자입니다.
이번 글에서 실무에서 한 번쯤은 만나게 되는 ‘따닥’ 이슈에 대해 트러블 슈팅 과정을 담아보려 해요. 단순 해결책이 아닌, 과정을 통해 실무에서는 어떻게 문제를 찾아 해결해 나가는지 궁금하신 분들에게 적당한 가이드가 되었으면 좋겠습니다.
문제가 뭐야?
와디즈에는 [결제 정보 관리]라는 화면이 있어요.

결제 카드 등록 화면
카드는 1개만 등록할 수 있는데요, 간헐적으로 중복으로 등록되는 버그가 발생했어요. Redis 분산 락을 걸어 빈도수를 제로에 가깝게 줄였지만, 여전히 근원지는 알기 어려웠어요. 특히 재연이 어려운 탓에 골치가 아팠는데요. 정확한 뿌리를 찾고자! 여정을 떠났습니다. 🏃♀️🏃♂️
개발계 재연 성공!
소위 ‘따닥’은 단순 유저 행위로 보기보다는 API가 중복으로 호출됐다는 관점이 더 정확해요. 아주 빠른 속도 등 개발자들이 예상하지 못한 상황에서 말이죠. 이것저것 시도하다 크롬 개발자 도구에서 아래의 경우를 찾았습니다. 마지막 두 줄을 보면 문제의 API가 중복으로 호출된 것이 보여요.
[XHR] 'POST: /.../../get'
[XHR] 'POST: /.../../add'
[XHR] 'POST: /.../../add'
클라이언트에서 두 번 호출하고 있는 것이 문제일까?
보통은 프론트엔드 개발자와 함께, 버튼 클릭을 1번만 가능하도록 고정시킬 겁니다. 하지만 현재는 그렇게 진행하기 어려운데요. 그 이유는 ‘요구사항에서 관련된 정책이 존재하는가?’에 있어요. 유저 행위를 규정하는 것은 요구사항이자, 정책이에요. 아래는 카드 등록 API Flow Chart입니다.
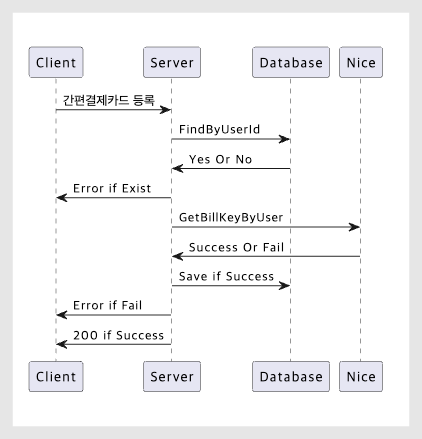
flow chart
즉, 여기서 정책은 유저가 몇 번을 요청하든 서버는 알아서 필터링해 하나의 카드만 갖도록 하는 것이에요. 클라이언트에서 몇 번이고 요청하는 일은 전혀 문제 될 것이 아니에요. 그래서 이번 이슈는 서버 단에서 발생한 문제로 봐야 해요. 서버에서 처리해야 하는 것이죠.
무언가 특이점이 있을 거야
그럼, 서버는 어떤 식으로 동작했어야 할까요? 정책대로라면, 하나의 카드만 가져야 하므로 2장이 들어온다면 1장은 삭제해야 합니다. 하지만 삭제하지 않고, 요청을 그대로 받아서 새롭게 등록하고 있었죠. 여기서 우리는 이슈를 재정의할 수 있습니다. ‘특정 상황에서 서버의 방어 로직이 동작하지 않는다.’
매 호출 시에 발생하는 일이 아닌, 어떤 ‘특정한 조건’에서만 발생하는 일로써 이제는 그 ‘조건’을 찾아야 해요.
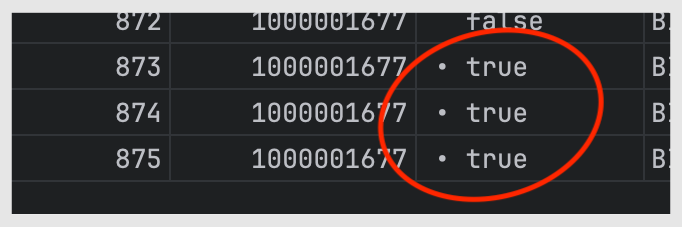
3개 이상도 중복이 발생하고 있는 상황
특이한 건 중복이 쌓이는 순간에는 항상 ‘화면 멈춤 증상’이 있다는 거예요.
카드 등록 화면
위 화면에서 [다음] 버튼을 누르면 화면이 넘어가야 하는데 멈춰있는 상황이 발생했죠. 심지어 개발자 도구에 API를 호출한 내역도 찍히지 않았어요. 이게 굉장한 힌트가 되었는데요!
Chrome 브라우저는 API 호출 후 Timeout에 빠진다면 스스로 호출을 재시도해요. 다시 말해서 Timeout에 이르기까지 어떻게든 응답을 기다려 개발자 도구에 남기는 겁니다. 그런데 찍히지 않았다는 건 서버가 응답을 주지 않는 상황이에요.
서버는 어째서 계속 요청을 잡고 있는 걸까요? 로직은 정책대로 구현되어 있어서, 중복으로 요청이 왔을 시 필터링해 하나만 받고 하나는 차버렸어야 하는데 말이죠. 아래의 로그를 통해 범인은 확실히 서버로 기울었습니다.
2023-12-28 13:45:56.081 [wadiz] Call started
...(생략)
2023-12-28 13:46:27.408 [wadiz] Call finished successfully
서버는 왜 필터링 하지 못할까?
하나의 요청을 받고, 이후 두 번째 요청을 받았다면 처음 요청 시 생성된 카드는 삭제되어야 해요. 이게 되지 않았다는 것은 동시에 접근했다는 의미입니다. 그리고 동시 접근을 제어하기 위한 조치는 글의 서론에 언급한 것처럼 이미 진행되었어요.
레디스(Redis) 분산 락 문제는 아닐거야..! 레디스는 싱글 스레드에서 동작한다는 특징을 기반으로 동시성 제어를 도와줄 수 있어 분산 시스템 환경에서 클러스터링을 통해 분산 락 목적으로 쓰이기도 해요. 게다가 이는 잘 알려진 방법으로 그 효과는 이미 많은 사례로 증명되었어요.
가장 믿을만한 녀석이 문제일 수 있다니? 아닐 것이라 믿는 순간 대혼란이 시작됩니다. 그 때문에 마구잡이로 조사하기 시작했어요.
1) 비관적 락(pessimistic lock)을 걸지 않아서 그런 건가? NO
낙관적 락은 ‘문제가 없을 거야’라고 가정하고 유연한 락을 거는 반면, 비관적 락은 ‘이거 무조건 문제 생겨’라고 가정하여 시작부터 락을 걸어버립니다.
레디스가 제 역할을 정상적으로 수행한다 해도, 한 스레드의 제어권이 해제되는 시점에서 다른 스레드가 제어권을 획득하는 시점이 아주 완벽하게 맞아 든다면, 락을 건다고 해도 우연한 중복은 여전히 가능한 것이 아닌가? 의문이었죠.
비관적 락을 걸어 아예 입구부터 틀어 막아버릴까? 생각했지만 선택하지 않았어요. 비관적 락은 동시성 제어를 가장 높은 레벨로 올려버리기 때문에 그 만큼 과부하라는 키워드와 트레이드-오프(trade-off) 관계가 되기 때문이에요. 이 결정으로 어떤 사이드 이펙트가 있을지 감히 예상되지 않았습니다. 최후의 수단으로 남겨둬야겠지요.
2) mybatis는 왜 에러를 뱉지 않지? NO
소스코드에서도 이상한 점을 발견했어요.
빌키접근클래스.selectOne(userId);단건을 조회하는 로직인데요. 중복이 발생했으니, SelectOne()은 오류를 일으켜야 합니다.이슈가 발생한 프로젝트엔 MyBatis 코드가 남아있었는데요. 이유를 알기 위해 구현체를 뜯어보기 시작했어요.
public <T> T selectOne(String statement, Object parameter) {
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
상위 레벨에서는 selectOne() 이라는 이름을 쓰지만 실제 내부에서는 selectList로 동작해요. 그리고 size가 1보다 크다면 예외를 던져야 한다는 걸 알 수 있습니다.
그런데 Exception이 발생하지 않았던 겁니다. 그 이유를 쿼리에서 찾아볼 수 있었어요.
SELECT 조회할 데이터
FROM A테이블 ...
LEFT JOIN ...
WHERE ...
ORDER BY A테이블.Registered
LIMIT 1;어떤 이유에서인지 ORDER BY와 LIMIT을 통해 리스트를 자르고 있었어요! 팀원의 조언에서 그 이유를 찾을 수 있었는데요. 이전 레거시 프로젝트라고 했던 것 기억하시나요? 과거 회사에서 ORDER BY와 LIMIT를 수행하는 로직을 만들었음을 알게 되었어요. 저는 MyBatis 특징상 IDE의 도움을 받지 못해 찾지 못하고 있던 겁니다. (ORM 최고…)
이 외에도 여러 곳을 들쑤셨지만, 큰 힌트를 얻지 못했어요. 하지만 적어도 개선 방안 하나를 얻을 순 있었죠. 코드를 수정해 ORDER BY의 정렬 기준을 반대로 가져간다면, 데이터가 중복으로 쌓이더라도 삭제 로직을 태울 수 있다는 것.
하지만 이 여정의 목적은 예방에 있죠! 중복 데이터 제거가 아니라 중복 자체가 되지 않아야 합니다. 그렇다면 여전히 서버는 왜 필터링 하지 못하는가? 의문은 풀리지 않았어요.
범인을 찾았다.
아래의 로그를 시간과 함께 주목해 주세요!
첫 번째 로그
[17:46:03.797][http-bio-8080-exec-2] INFO - delete() | userID = 100, targetSeq = 887
[17:46:03.797][http-bio-8080-exec-2] INFO - delete() | delete success
두 번째 로그
[17:46:30.791][http-bio-8080-exec-9] INFO - delete() | userID = 100, targetSeq = 887
[17:46:30.791][http-bio-8080-exec-9] INFO - delete() | delete success
세 번째 로그
[17:46:57.931][http-bio-8080-exec-5] INFO - delete() | userID = 100, targetSeq = 887
[17:46:57.931][http-bio-8080-exec-5] INFO - delete() | delete success
현재 DB에는 887번이 최신으로 등록되어 있어요. 새로운 카드가 등록된다면 887번을 삭제한 뒤, 본인은 888번으로 삽입될 거고요. 03초 요청, 30초 요청, 57초 요청, 모두가 887을 삭제하려고 시도합니다. 다시 말해서 모두가 ‘내가 진짜 888번이야’라고 주장하는 상황이에요.
어째서 이러한 경쟁상태(Race Condition)에 빠진 걸까요? 이제는 ‘설마 레디스(Redis)가 제 기능을 못 하고 있나?’라는 의심으로 이어집니다.
Redis를 뜯어보자.
파악에 앞서 Redis에 대한 개념과 ‘따닥’이슈를 막기 위해서 레디스를 어떻게 활용할지 간단히 설명할게요.
1) 레디스 기초
레디스는 싱글-스레드로 동작합니다. 그래서 단일 레디스 노드를 구축하면 동시성 문제가 발생하지 않아요. 리소스에 ‘어떤 값’을 설정하면 다른 스레드에 접근을 차단할 수 있는데요. 이것을 락(LOCK)이라고 표현합니다. 즉, 실제 LOCK 기능을 Redis에서 제공하는 것이 아니라 Redis의 특징을 활용해 사용자(개발자)가 LOCK를 만들어내는 것으로 생각하면 돼요.
setnx(key, value) // set if not exist위와 같은 방식으로 현재 키에 해당하는 값이 없다면 값을 추가하도록 설정하고, 아래와 같은 방식으로 특정 조건(주의)에 삭제하거나 유효 시간에 자동 소멸하도록 설정해 주면 돼요.
if(...) {
del(key) // or expire
}하지만 이 방식은 SPOF(Single Point Of Failure)가 되기도 해요. 단일 노드이기 때문인데요. 다운될 경우를 대비한 보완이 필요하고 그것이 분산 락으로 이어집니다.
2) 레디스 활용 (분산락)
SPOF를 보완하기 위한 가장 간단한 방법으로는 Master-Slave Replication을 구축하는 거예요. 그러면 분산 환경에서도 lock을 걸어줄 수 있죠. 그러나 여기에도 이슈가 있어요. 마스터에 문제가 생길 경우, Slave(슬레이브)가 승격해 해결할 것으로 보이지만, 레디스 복제는 비동기식으로 동작하기 때문에 경쟁 상태(Race Condition)에 빠질 수 있어요. 그래서 Clustering을 하더라도 여전히 경쟁 상태에 빠질 수 있다는 가능성은 남아있죠. 예를 들면 다음과 같아요.
- A의 요청이 들어오고 Master에서 Lock을 획득합니다.
- Master에서 Slave로 전송되기 전에 Master가 다운됩니다.
- Slave가 Master로 승격합니다.
- B의 요청이 들어오고 A와 동일한 리소스에 대한 Lock을 획득합니다.
이제 레디스에서는 RedLock이라고 하는 알고리즘을 제안했어요. 기존 분산락 알고리즘의 성능을 높인 알고리즘인데요. 락의 획득과 만료에 대해 시간 단위 또는 락 경쟁에서의 획득 기준 등 몇 가지 요소를 바꿨지만, 이 또한 온전하지 못합니다.
3) 본격 Redis 뜯어보니
클러스터 설정 파일(.conf)부터 프로파일(profile) 환경 별 차이가 있는지, 등등 낱낱이 검토해 본 결과, 문제가 될 만한 것은 보이지 않았어요.
범인일 것이라 예상한 것이 빗나가는 순간! 다행히 결정적인 힌트를 얻었습니다. 위 내용에서 레드락(RedLock)에 대해 언급했는데요. 레드락 한계에 관련된 내용 중 Network Delay에 대한 내용이 심상치 않았어요.
등잔 밑이 어둡다. Back to Basic
만약 GC가 관여하고 Lock이 필요한 작업이 있다고 할 때, 다음 이슈가 발생할 수 있어요.
- A가 분산 락을 획득한다.
- 갑작스럽게 어플리케이션 중지가 발생하고 분산 락이 만료된다. (레디스가 아닌 서비스가 내려간 상황)
- B가 동일 리소스에 분산 락을 획득한다.
- A의 어플리케이션이 복구되고 작업을 재개한다.
- 동시성 이슈 발생 💥
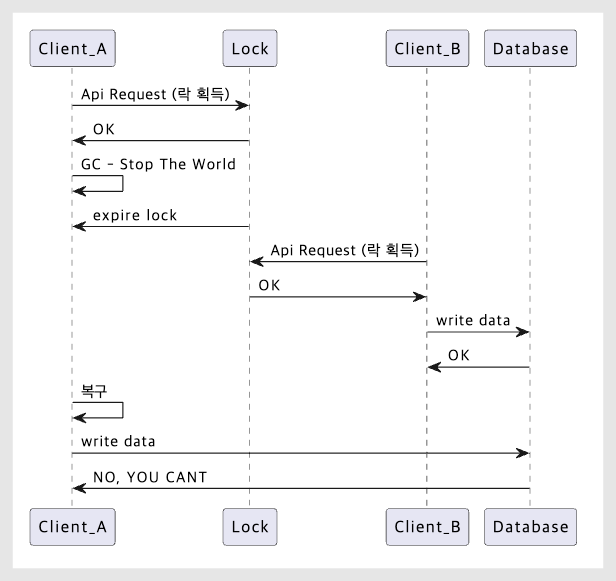
위의 상황을 흐름으로 표현
GC 시간이 얼마나 짧은데, 그사이에 그럴 수가 있나?! 가능하다고 합니다. 실제로 Hbase의 사례에서는 이 문제를 겪은 뒤 GC 튜닝에 대한 가이드를 제시하고 있어요. 그리고 이것과 비슷한 상황이 GC로 인한 Stop the world가 아닌 네트워크 딜레이에 의해서도 발생한다고 해요.
제일 처음 생각한 원인이 ‘네트워크 딜레이’였는데요. 그 원인을 추적하던 중 다시 본론으로 돌아왔네요. 전체 코드를 다시 보니 지나쳤던 로직이 눈에 들어왔어요. (Back to Basic이라는 말이 있죠.)
객체지향을 활용한 좋은 설계의 기본은 높은 응집도(high cohesion)와 낮은 결합도(low coupling)예요. 유명한 예로, 만약 여러분이 자동차의 시트를 교체해야 하는데 핸들까지 뜯어야 한다면? 핸들이 시트에 강결합되어 앞으로 어떤 일이 발생하든, 계속 의존된 상태로 진행하게 되죠.
문제의 비즈니스 로직을 주목해 주세요.
...
유저_정보_가져오기();
유저_정보_검증하기();
...
외부사에_결제키_요청하기();
기타_오류_검증하기();
...
저장하기();긴 코드를 다 볼 필요 없이 ‘어떤 역할인가?’를 기준으로 나열해 보면 위와 비슷한 모양이 나옵니다. 중간에 “외부사에_결제키_요청하기()” 메소드가 보이죠. 게다가 동기 방식으로 요청을 던지고 있어서 결합도가 아주 높은 상황이라는 게 눈에 띄었어요. 이 관점으로 이슈 상황을 테스트하면서 물증을 얻을 수 있었습니다.
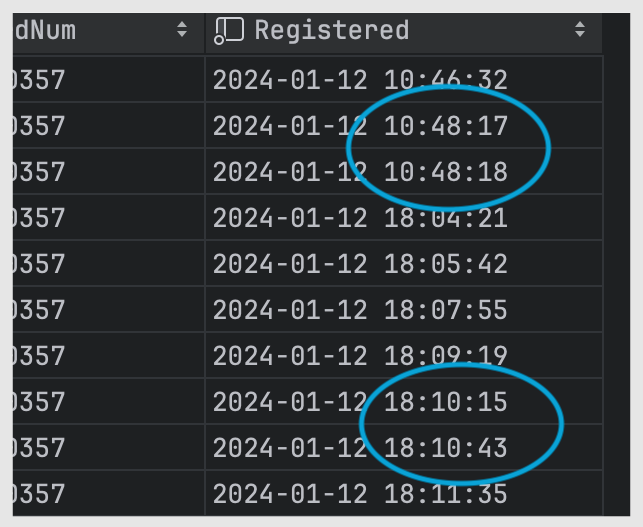
mysql에 데이터를 저장한 시점
첫 번째 상황은 1초 사이 중복이 발생했고, 두 번째 상황은 약 30초가 걸렸어요. 딜레이 구간이 최대 30초가 넘어갈 수도 있다는 뜻인데요. 사내 망에서 이 정도 딜레이는 발생하지 않아요. 외부의 어떤 응답을 기다리고 있다는 의미일 수 있겠죠.
이어서 로그를 다시 봅니다.
[10:22:28.983][http-bio-8080-exec-7] INFO - ClientConnector.request() | request
[10:22:28.985][http-bio-8080-exec-7] INFO - ClientConnector.request() | response
[10:22:28.986][http-bio-8080-exec-7] INFO - ClientConnector.request() | end성공 케이스에서는 1초 이내에 통신 요청부터 응답, 커넥션 종료까지 수행돼요. 그러나 중복 키가 발생하는 상황에서는 달랐습니다.
[10:23:25.832][http-bio-8080-exec-7] INFO - ClientConnector.request() | request
...
[10:23:38.863][http-bio-8080-exec-7] INFO - ClientConnector.request() | response
[10:23:38.865][http-bio-8080-exec-7] INFO - ClientConnector.request() | end응답까지 약 13초가 걸렸고 커넥션 종료는 빠르게 이어집니다.
대기 시간이 더 길어지는 경우도 있었어요.
[10:24:19.498][http-bio-8080-exec-7] INFO - ClientConnector.request() | request
[10:24:42.510][http-bio-8080-exec-4] DEBUG - AbstractHandlerMethodMapping...약 30초가 걸리기까지 응답은 어디 갔는지 보이질 않아요. 다른 스레드의 요청을 수행하고 있죠.
범인은 잡았지만 그래도 남은 의문이 있어요. 외부 서비스 의존으로 인한 네트워크 딜레이가 원인이라면 레디스에 왜 안 걸렸을까요?
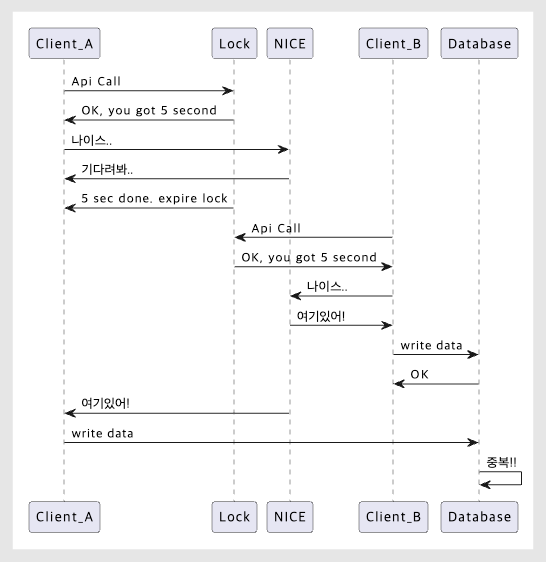
중복 발생 통신
기존에는 레디스 분산 락의 expired time을 5초로 잡아두었어요. 그래서 위 API Flow처럼 외부사가 응답을 주는 시간이 5초(기준)를 넘어가면 아직 프로세스가 끝나지 않았음에도 다음 요청이 Lock을 획득할 수 있기 때문에 레디스 입장에선 아무 문제가 없는 거였죠.
(왜 테이블에서 막히지 않는지 의아해하실 수도 있을 텐데요. 과거 정규화 당시 해당 테이블에는 별도로 키를 걸어두지 않아서 테이블은 그저 입력받는 대로 저장 역할만 수행해요.)
결국, 로직 중 외부 API에 동기 상태로 강결합되어 있는 녀석으로 인해 예상치 못한(탐색 되지 않는) 네트워크 딜레이가 발생한 것이 중복 저장의 원인이었어요. 이렇게 단순한 원인을 찾기까지 이리저리 정말 많은 곳을 탐색했네요. 😂
이렇게 개선했어요!
시도해 볼 만한 것들은 여러 가지가 있었어요. 저장되는 테이블에 락을 걸어줄 수도 있고, 주키퍼(Zookeeper)와 같은 시스템 도입으로 정확성을 높일 수도 있죠. 또는 레디스에 펜싱 토큰을 넣어서 정합성 체크를 추가로 진행할 수도 있습니다. 호출 방식을 비동기로 전환하여 결합도를 낮출 수도 있어요. 결론만 말하면 레디스(Redis)의 LOCK 시간을 증가시키는 방향으로 개선해 나가려고 했어요.
소거법으로 선택지를 줄여 나갔는데요! 가급적 테이블 구조는 건드리지 않고 싶었고, 다른 시스템 도입 역시 러닝커브를 고려해야 해요. 레디스 동작 방식 변경은 레거시 프로젝트인 만큼 사이드 임팩트 범위를 헤아리기 쉽지 않았습니다. 또 비즈니스 로직 상 응답이 필요했기에 비동기 전환도 어려웠어요.
다행인 건 해당 기능은 과한 트래픽을 받지 않는다는 점이었습니다. Lock 시간을 늘리는 것이 과부하를 주진 않겠다는 판단으로 선택할 수 있었어요. 그 결과, 최근 Lock 시간을 새로운 기준으로 증가시켰을 때, 1건도 중복이 발생하지 않았답니다.
마치며
트러블슈팅 과정 어떠셨나요? 요즘처럼 편리한 도구가 많이 생긴 시대에 가장 기본에서 정답을 찾았어요. 여러 기술이 등장했고, 빗겨나간 의심과 합리적인 결정까지, 개발자의 희로애락을 보여드린 것 같네요. 이제 입사한 지 한 달이 지나가고 있는 시점에 조금이나마 팀과 조직에 기여하게 된 것 같아서 뿌듯합니다.
아직 서비스 구조에 미숙한 탓에 시간은 걸렸지만, 함께 해주신 동료분들 덕분에 결말에 도달할 수 있었어요. 실무에서 트러블 슈팅도 크게 다를 것 없이, 결국 집요함의 싸움이라는 것을 끝으로 글을 마무리합니다. 감사합니다!
👉 와디즈 백엔드 개발자, 비즈니스개발팀에 대해 더 궁금하다면? (인터뷰 보러가기)
👉 와디즈는 자바 백엔드 개발자 채용 중!




