안녕하세요. 와디즈에서 서비스플랫폼팀 입니다.
서비스플랫폼팀은 와디즈의 인프라 및 데이터베이스를 비롯하여 다양한 공통 서비스(결제, 메인, 알림, 파일)를 개발, 운영하는 팀이에요.
증가하는 데이터, 효율적으로 정리하기
많은 기업과 사용자들로부터 생성 및 재가공된 데이터들은 매년 상상을 초월하는 수치로 증가하고 있습니다. 2010년 이후부터 볼륨은 제타바이트 크기를 넘어 엄청난 규모로 증가하고 있지요.
그 때문에 보안성을 강화하기 위해 중요 데이터를 암호화하거나, 높은 가용성을 위해 이중화, 삼중화로 데이터를 관리해야 하는 경우가 발생했습니다. 다양한 기기들의 접근성 및 호환성을 높이기 위해 여러 크기 및 포맷으로 지원해야 하는 것이 일반적인 상황이 되었지요.
와디즈의 경우에도 증가하는 데이터를 저장하고, 안정적으로 운영하기 위해 별도의 공유 스토리지를 활용하고 있습니다. GlusterFS를 활용하여, NAS(Network Attached Storage) 형태의 스토리지를 구성하고 있어요. GlusterFS는 Scale-out이 가능한 Software Defined 스토리지입니다.
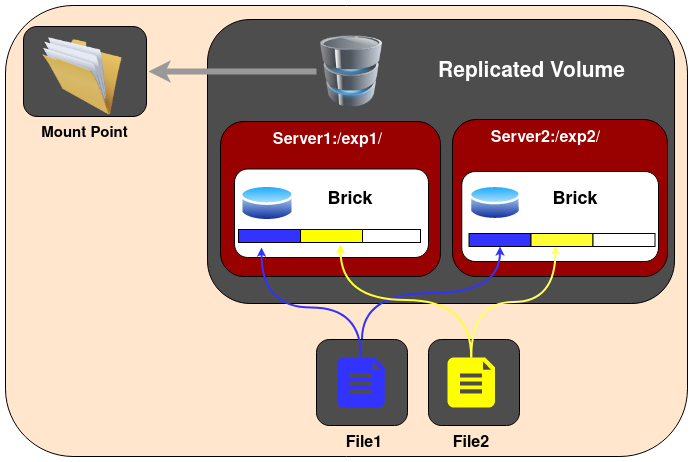
GlusterFS 아키텍처 (출처: GlusterFS)
GlusterFS는 기본적으로 복제된 볼륨을 통해 데이터 손실을 예방할 수 있다는 장점이 있어요. 또 쉽게 Brick 단위로 볼륨을 확장할 수도 있습니다.
하지만 이는 NAS가 가지는 한계를 똑같이 가지고 있어요. 일정 볼륨 이상일 경우 상대적으로 느려지는 문제점이 있습니다. 특히 레거시 환경에서는 초기 구성된 네트워크 대역폭이 늘어난 스토리지 규모를 소화하기에 어려움이 있지요. 운영 중 새로운 Brick을 추가한 후 GlusterFS 리밸런싱하는 과정에서 오랜 시간 네트워크 병목 현상을 마주하게 될 수도 있습니다. 여러 개의 NIC(Network Interface Card)를 논리적으로 하나로 묶어 네트워크 본딩을 통해 어느 정도 대역폭을 향상할 수는 있어요. 하지만 다른 물리 장비들 간의 네트워크 대역폭이 전체적으로 개선되지 않으면, 이 또한 단기적인 미봉책에 그치게 됩니다.
우리는 증가하는 스토리지 니즈에 대응하기 위해 단순히 스토리지 증설에서 오는 한계를 인지했어요. On-premise에 집중되는 네트워크 트래픽 부하도 줄이기 위해 퍼블릭 클라우드 스토리지를 적극적으로 활용하기로 했습니다. 스토리지 내에 분류되지 않고, 정리하기 힘든 부분들을 단계적으로 개선하여 레거시에서 오는 한계도 극복하기로 했지요.
클라우드 스토리지 활용하기
클라우드 스토리지를 활용하고 전환하기 위해 다음과 같은 프로세스를 정립했습니다.
Labeling → Syncing → Storing → Archiving → Accessing
기존의 우리는 분산 스토리지 솔루션 중의 하나인 GlusterFS를 활용하여 다양한 용도와 목적의 데이터를 운영하고 있었어요. 하지만 시간이 지나갈수록 정리된 데이터의 기준과 목적이 모호해지면서 관리에 여러 어려움이 발생하기 시작했습니다.
그래서 첫 번째로 정립되어 하는 부분이 데이터의 Labeling이었습니다.
데이터 Labeling
- 무엇이 중요한 데이터인가?
- 어떠한 목적으로 사용 중인 데이터인가?
- 특정기간 동안 보관하며 관리해야 하는 것인가?
데이터에서 중요한 것은 ‘보안’이에요. 데이터 접근에 대한 권한 적용뿐만 아니라, 저장하고 다운로드할 때에도 다양한 장치를 통해 안정성을 확보하는 것이 중요합니다. 누구나 접근 가능한 파일(이미지, 제품에 대한 설명 동영상 등)과 제품을 심사하고 관리할 때 필요한 파일을 명확하게 구분할 필요가 생겼습니다. 그래서 퍼블릭 액세스가 가능한 파일을 기준으로, 목적에 따라 구분하여 관리할 수 있게끔 데이터를 분류하여 Labeling 하는 것이 클라우드 스토리지로 전환할 기반을 마련해준다 생각했습니다.

데이터 Syncing
퍼블릭 액세스가 가능한 데이터를 AWS S3(Simple Cloud Storage)로 단일 또는 주기적인 업로드를 하기 위해서는 여러 솔루션이 있어요. 간단하게 AWS CLI command 에서 Storage gateway, Data sync 등을 활용할 수가 있지요.
몇 가지 유용한 command를 공유합니다.
- AWS S3 cp –recursive on-premise//files s3://in-cloud/files
- AWS S3 sync on-premise//files s3://in-cloud/files –only-show-errors
업로드 이후 나머지 파일들만 업로드 시 sync 명령어를 사용합니다. max_concurrent_requests (default value = 10) 파라미터를 활용하여 동시 업로드 요청 수를 증가할 수는 있어요. 하지만 sync의 경우 파일 비교에 많은 리소스(CPU, Memory)가 들어 아쉬움이 있습니다. 그래서 단순 파일 복사할 때 활용하기 편합니다.
Data Sync를 활용할 경우, CLI에 비해 속도 조절 및 성능의 장점은 많지만, 일부 NAS 환경 활용에 어려움이 있어요. 특히 GlusterFS는 지원하지 않아 실제 활용을 적용하진 못했습니다. (추후 적용 계획이 있다는 피드백을 받았습니다.)
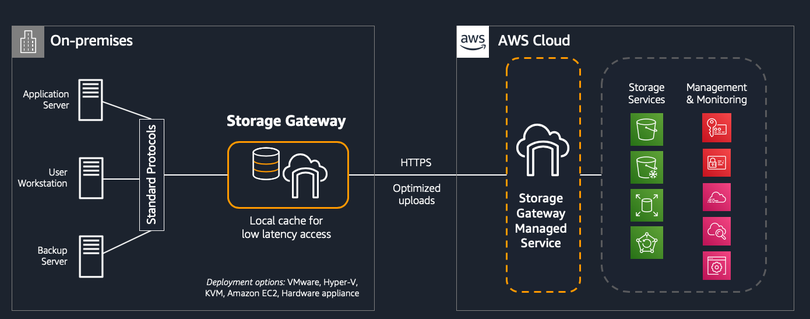
High-level architecture of Storage Gateway (출처: Amazon)
Storage Gateway는 위 가이드를 통해 쉽게 적용할 수 있어요. 크게 3가지 타입을 제공하고 있습니다.
File Gateway
- NFS(네트워크 파일 시스템) 및 SMB(서버 메시지 블록)와 같은 파일 프로토콜을 사용하여 Amazon S3에서 객체를 저장하고 검색할 수 있습니다.
- 지연 시간이 짧은 액세스를 위해 가장 최근에 사용된 데이터가 게이트웨이에 캐시 되고, 게이트웨이에서 데이터 센터와 AWS 간 데이터 전송을 모두 관리합니다.
Volume Gateway
- iSCSI 연결을 사용하여 온프레미스 애플리케이션에 블록 스토리지를 제공합니다.
- 사용자는 특정 시점의 볼륨 복사본을 생성할 수 있고 이는 AWS에 Amazon EBS 스냅샷으로 저장됩니다.
Tape Gateway
- 가상 미디어 체인저, 가상 테이프 드라이브 및 가상 테이프로 구성된 iSCSI 가상 테이프 라이브러리(VTL) 인터페이스를 백업 애플리케이션에 제공합니다.
- 백업 애플리케이션은 가상 미디어 체인저를 사용해 가상 테이프를 가상 테이프 드라이브에 탑재하여 가상 테이프에서 데이터를 읽기 쓰기가 가능합니다.
Storage Gateway의 File Gateway를 활용할 경우, CLI보다 안정적일 순 있어요. 하지만 업로드 및 다운로드 속도 조절을 위한 항목이 없다는 단점이 있습니다. 유휴 시점에도 네트워크 리소스를 사용한다는 점이, 네트워크 대역폭이 충분하지 않은 환경에서는 주의가 필요합니다.
데이터 Storing 그리고 Archiving
우리는 프라이빗 액세스가 필요한 파일들은 on-premise 환경에 MinIO(Object Storage)를 활용하여 저장되도록 했어요. 퍼블릭 액세스가 가능한 파일들은 AWS S3를 활용했습니다.
S3에 서로 관련된 모든 파일들을 한번에 전환하여 저장, 관리하는 것이 효율적이라는 데는 동의합니다. 하지만 기존 백엔드 서비스의 연동과 모든 파일들의 Labeling은 충분한 시간을 필요로 하는 작업이에요. 연도별, 적용 서비스별 등 단계적인 전환이 레거시를 포함한 스토리지 서비스를 안정적으로 운영하는 데 효과적이라 생각했습니다.
또한 AWS S3 Glacier를 활용하면, 비용에 있어 효율적으로 파일들을 아카이빙 할 수가 있어요. 다만 이를 위해서는 제공되는 다양한 스토리지 클래스들의 충분한 이해가 필요합니다.
데이터 Accessing
이렇게 되니, 하이브리드(Hybrid)한 스토리지 환경에서 데이터 Accessing은 고민하지 않을 수가 없었어요. 새롭게 구성한 모든 파일이 똑같은 환경을 바라본다면, 수월하게 정책을 정립할 수 있습니다. 하지만 기간이나 목적에 따라 다른 스토리지 환경으로 나누어진 상황에서는 on-premise 환경에 저장된 데이터와 S3로 Migration 된 데이터에 심리스(Seamless)한 접근을 제공해야 했습니다.
우리는 STON 서버의 가상 호스트 링크 기능을 활용했어요. On-premise 내 스토리지에서 부재한 파일들을 퍼블릭 클라우드 환경에 액세스가 가능하도록 했습니다.
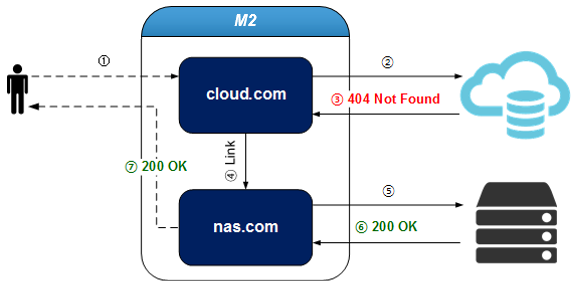
가상 호스트 링크 설명 (cloud.com에 없는 콘텐츠는 nas.com이 처리한다 / 출처: readthedocs)
또한, 기존 CDN 서비스에서 제공되는 다양한 이미지 툴링(resize, optimize, watermark 등)을 동일하게 활용하기 위해서도 해당 기능은 효과적이었죠.
클라우드 스토리지 활용의 결과
‘클라우드 스토리지 활용’이라는 일련의 과정을 통해 1) 스토리지 증가에 기민하게 대응이 가능한 환경을 마련할 수 있게 되었어요. 이전에는 스토리지 구매부터 인계, PM(Preventive Maintenance)을 통한 증설까지, 짧게는 2주 길게는 3달의 시간이 필요했습니다. 사용량만큼 비용을 지불하는 클라우드 스토리지는 이를 좀 더 빠르게 대응할 수 있게 해주었지요.
2) on-premise에 집중되는 네트워크 트래픽 부하를 클라우드로 전환해 좀 더 안정적인 서비스 제공도 가능해졌어요. 또, 3) 새로운 기획과 좋은 아이디어가 쏟아져 나오는 스타트업의 특성상, 빠르게 개발하고 고객에게 기능을 제공해야 하는데요, 이때 레거시 백엔드 서비스를 새롭게 개발하지 않고도 기존 스토리지 환경을 개선할 수 있게 되었습니다.
퍼블릭 클라우드는 분명 다양하고 편리한 솔루션이 많이 존재합니다. 계속해서 발전해 나가고 있기도 하고요.
다만 Lift and Shift처럼 단순 Migration 전략이 아닌, 레거시 환경을 개선해 나가면서 클라우드를 전환하기 위해서는 많은 고민과 솔루션에 대한 충분한 이해가 필요합니다.
이미 구축된 레거시 환경은 어제의 영광입니다. 개선해야 하는 큰 짐으로만 치부되기에는 아쉬움이 남죠. 어제의 신기술이 오늘은 레거시가 되어버리는 IT 환경에서는 레거시를 안고 함께 개선해 나가는 것이 IT 개발의 꽃이자 묘미가 아닐까요 😉
*참고자료
The Gartner Top 6 Trends for Infrastructure & Operations in 2022
https://towardsdatascience.com/22-predictions-about-the-software-development-trends-in-2022-fcc82c263788
Total data volume worldwide 2010-2025 | Statista
Architecture – Gluster Docs
What Is Amazon Storage Gateway and How to Deploy It?
14장. 가상호스트 고급기법 — STON Edge Server documentation
궁금한 내용이 남아 있나요? 👀
서비스플랫폼팀의 이야기가 궁금하다면? 👉 클릭