
Hello! I’m a backend developer on the Wadiz Funding Development Team.
In this post, we’ll take a look at the "tick-tick" issuethat you’re bound to encounter at least once in your daily work. Rather than offering a simple solution, I hope this serves as a useful guide for those curious about how problems are identified and resolved in real-world scenarios.
What's the problem?
Wadizhas a screen called [Manage Payment Information].

Payment Card Registration Screen
Although only one card is supposed to be registered, a bug occasionally caused duplicate registrations. We implemented a Redis distributed lock to reduce the frequency to near zero, but the root cause remained elusive. It was particularly frustrating because the issue was hard to reproduce. Determined to find the exact source, we set out on a quest! 🏃♀️🏃♂️
Successful reproduction in the development environment!
Rather than viewing the so-called "tap" as a simple user action, that the API was called redundantly—especially in situations developers didn’t anticipate, such as extremely high speeds. After trying various things, I found the following case in Chrome DevTools. If you look at the last two lines, you can see that the API in question was called twice.
[XHR] 'POST: /.../../get'
[XHR] 'POST: /.../../add'
[XHR] 'POST: /.../../add'
Is the problem that it's being called twice by the client?
Normally, we would work with a front-end developer to ensure that a button can only be clicked once. However, that’s not feasible at the moment. The reason is: ‘'Are there any relevant policies in the requirements?'’ Defining user behavior is both a requirement and a policy. Below is the card registration API flowchart.
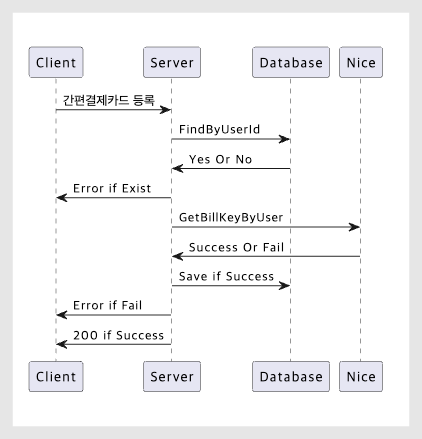
flowchart
In other words, the policy here is that no matter how many times the user makes a request, the server automatically filters the results so that only one card is displayed. The fact that the client makes multiple requests is not an issue at all. Therefore, this issue should be viewed as a problem originating on the server side. It is the server’s responsibility.
There must be something unusual about it.
So, how should the server have worked? According to the policy, only one card should be held, so if two cards were received, one should have been deleted. However, instead of deleting it, the server was accepting the request as is and registering a new one. Here, we can redefine the issue: ‘The server’s defense logic does not function in certain situations.’
This isn't something that happens with every call; it only occurs under certain "specific conditions," so now we need to identify those "conditions."
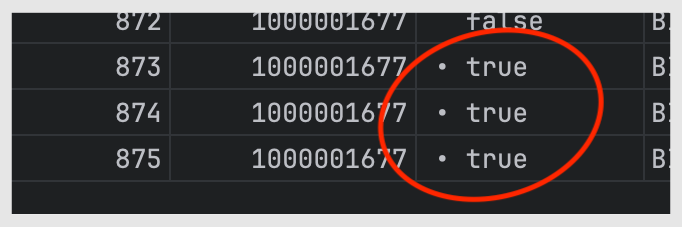
There are currently three or more instances of duplication
What's unusual is that whenever duplicates accumulate, the screen always freezes.screen freezing’ occurs.
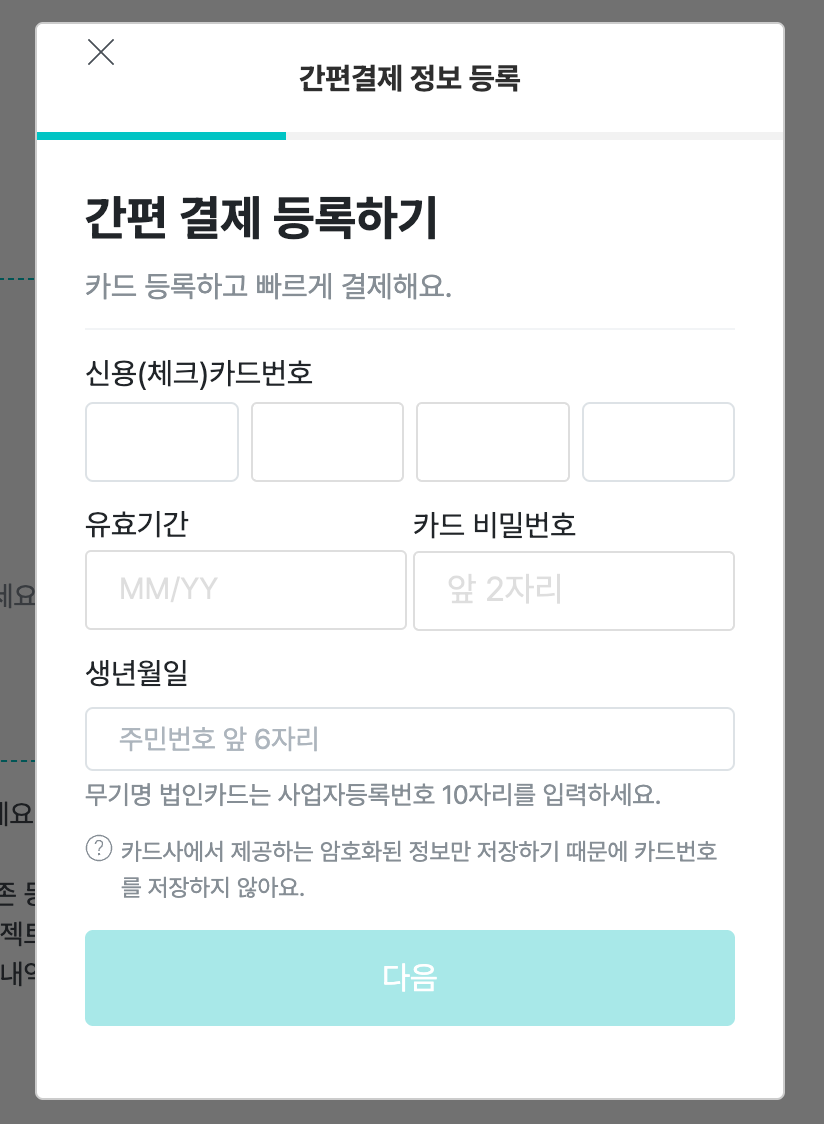
Card Registration Screen
When I clicked the [Next] button on the screen above, the page should have advanced, but it froze. In fact, there wasn’t even a record of the API call in the developer tools. This turned out to be a huge clue!
If the Chrome browser hits a timeout after making an API call, it automatically retries the request. In other words, it waits for a response until the timeout occurs and logs the result in the developer tools. However, if no log appears, it means the server is not responding.
Why is the server still processing requests? The logic was implemented according to the policy, so when duplicate requests arrived, it should have filtered them to accept only one and rejected the other. Based on the logs below, it’s clear that the server is the culprit.
2023-12-28 13:45:56.081 [wadiz] Call started
...(생략)
2023-12-28 13:46:27.408 [wadiz] Call finished successfully
Why can't the server filter this?
If you received one request and then a second request, the card created during the first request should be deleted. The fact that this did not happen means there was concurrent access. And as mentioned in the introduction to this article, measures to control concurrent access have already been implemented.
It probably isn't a Redis distributed lock issue...! Because Redis operates on a single thread, it can help manage concurrency, which is why it's often used for distributed locking in distributed system environments through clustering. Moreover, this is a well-established method, and its effectiveness has already been proven in numerous use cases.
Could the most trustworthy person actually be the problem? The moment I stopped believing that couldn't be true, everything fell into chaos. That's why I started investigating everything in sight.
1) Is it because I didn't set a pessimistic lock? NO
An optimistic lock assumes that "there won't be any problems" and applies a flexible lock, whereas a pessimistic lock assumes that "this is bound to cause problems" and applies a lock right from the start.
Even if Redis functions properly, I wondered: if the moment a thread releases control and the moment another thread acquires control align perfectly, wouldn’t accidental concurrency still be possible even with a lock in place?
I considered setting a pessimistic lock to block access right from the entrance, but I decided against it. That’s because a pessimistic lock raises concurrency control to the highest level, which creates a trade-off with the risk of overloading the system. I didn’t dare to predict what side effects this decision might have. I suppose I’ll have to keep it as a last resort.
2) Why doesn't MyBatis throw an error? NO
I also noticed something strange in the source code.
빌키접근클래스.selectOne(userId);This is the logic for retrieving a single record. Since a duplicate was found, SelectOne() should throw an error.There was some MyBatis code left in the project where the issue occurred. To figure out why, I started digging into the implementation.
public <T> T selectOne(String statement, Object parameter) {
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
Although it’s named `selectOne()` at the top level, it actually works as `selectList` internally. You can also see that it should throw an exception if `size` is greater than 1.
However, no exception was thrown. I was able to find the reason for this in the query.
SELECT 조회할 데이터
FROM A테이블 ...
LEFT JOIN ...
WHERE ...
ORDER BY A테이블.Registered
LIMIT 1;For some reason, I had been trimming the list using `ORDER BY` and `LIMIT`! I found the reason behind this thanks to a teammate’s advice. Do you remember that legacy project I mentioned earlier? I realized that I had actually written logic to perform `ORDER BY` and `LIMIT` back at my previous company. Because of the nature of MyBatis, I hadn’t been able to find it without the help of an IDE. (ORM is the best…)
I looked into several other areas as well, but didn't find any major clues. However, I was at least able to come up with one improvement. If I modify the code to reverse the sorting order in the ORDER BY clause, I can implement a deletion logic even if the data is duplicated.
However, the purpose of this journey is prevention! The goal isn’t to remove duplicate data, but to prevent duplicates from occurring in the first place. So why can’t the server filter them out? That question remains unanswered.
We've found the culprit.
Please take a look at the logs below, noting the times!
First log
[17:46:03.797][http-bio-8080-exec-2] INFO - delete() | userID = 100, targetSeq = 887
[17:46:03.797][http-bio-8080-exec-2] INFO - delete() | delete success
Second log
[17:46:30.791][http-bio-8080-exec-9] INFO - delete() | userID = 100, targetSeq = 887
[17:46:30.791][http-bio-8080-exec-9] INFO - delete() | delete success
Third Log
[17:46:57.931][http-bio-8080-exec-5] INFO - delete() | userID = 100, targetSeq = 887
[17:46:57.931][http-bio-8080-exec-5] INFO - delete() | delete success
Currently, number 887 is the latest entry in the database. If a new card is added, number 887 will be deleted, and your card will be inserted as number 888. Requests at 03 seconds, 30 seconds, and 57 seconds all attempt to delete No. 887. In other words, it’s a situation where everyone is claiming, “I’m the real No. 888.”
Why did this race condition occur? This naturally leads me to wonder, “Could Redis actually be malfunctioning?”
Let's take a closer look at Redis.
Before we dive in, I’ll briefly explain the basics of Redis and how to use it to prevent “tack” issues.
1) Redis Basics
Redis runs as a single-threaded application. Therefore, there are no concurrency issues when setting up a single Redis node. By setting a specific value on a resource, you can block access from other threads. This is referred to as a "lock." In other words, Redis does not actually provide a lock function; rather, you should think of it as the user (developer) creating a lock by leveraging Redis's features.
setnx(key, value) // set if not existIf there is no value corresponding to the current key, configure the system to add a value as shown above. To delete a value based on specific conditions (Note) or have it expire automatically after a certain period, configure the system as shown below.
if(...) {
del(key) // or expire
}However, this approach can also create a single point of failure (SPOF) because it relies on a single node. This requires a contingency plan in case the node goes down, which leads to the use of distributed locks.
2) Using Redis (Distributed Lock)
The simplest way to address the Single Point of Failure (SPOF) issue is to implement master-slave replication. This allows you to apply locks even in a distributed environment. However, there is a problem here as well. If an issue arises with the master, you might expect the slave to be promoted to take over, but since Redis replication operates asynchronously, it can lead to race conditions. Therefore, even with clustering, the possibility of falling into a race condition remains. For example:
- A sends a request and acquires a lock on the master.
- The master goes down before data is transferred to the slave.
- The slave is being promoted to master.
- A request is received from B, and a lock is acquired on the same resource as A.
Now, Redis has proposed an algorithm called RedLock. It is an algorithm designed to improve the performance of existing distributed lock algorithms. Although it modifies several factors—such as the time units for lock acquisition and expiration, as well as the criteria for acquiring locks in contention—it is not without its flaws.
3) A Deep Dive into Redis
After thoroughly reviewing everything from the cluster configuration file (.conf) to whether there were any differences between the various profile environments, I didn’t find anything that seemed to be causing the issue.
The moment my assumption about the culprit turned out to be wrong! Fortunately, I found a crucial clue. I mentioned RedLock earlier. Among the details regarding RedLock’s limitations, the section on "Network Delay"seemed particularly suspicious.
It's often hardest to see what's right under your nose. Back to Basics
If there is an operation that involves the garbage collector and requires a lock, the following issue may occur.
- A acquires the distributed lock.
- The application suddenly stops, and the distributed lock expires. (This occurs when the service—not Redis—goes down.)
- B acquires a distributed lock on the same resource.
- Application A is restored and resumes operation.
- Concurrency issue detected 💥
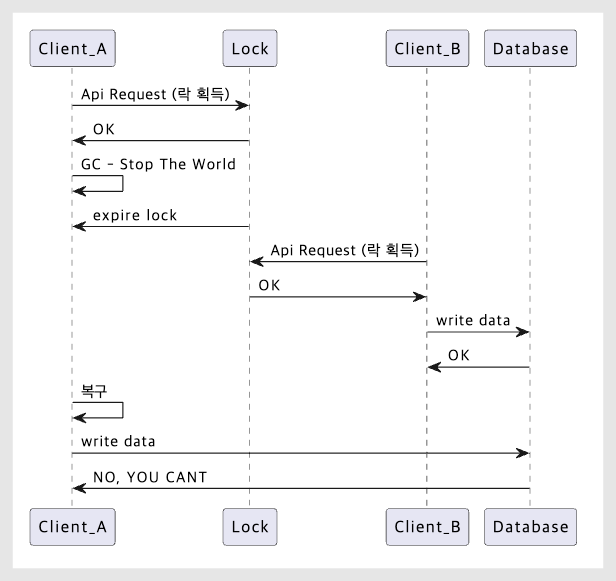
Depicting the above situation as a sequence
The GC cycle is so short—how is that even possible?! Apparently, it is. In fact, the HBase case, they encountered this issue and subsequently provided a guide on GC tuning. Furthermore, they say that similar situations can occur not just due to GC-induced "stop-the-world" events, but also due to network delays.
At first, I thought the cause was "network latency." But while I was investigating that, I ended up back at the root of the problem. When I looked over the entire code again, I noticed a piece of logic I had overlooked. (As the saying goes, "Back to basics.")
The foundation of good object-oriented design is high cohesion and low coupling. To give a well-known example, imagine you need to replace a car seat, but you have to remove the steering wheel as well. If the steering wheel is tightly coupled to the seat, whatever happens in the future, they will remain dependent on each other.
Please take a close look at the business logic in question.
...
유저_정보_가져오기();
유저_정보_검증하기();
...
외부사에_결제키_요청하기();
기타_오류_검증하기();
...
저장하기();If you list them based on the question "What role does it play?" without having to look at the entire code, you'll get something similar to what's shown above. In the middle, “request_payment_key_from_external_company()” method in the middle. Furthermore, since the request is being sent synchronously, it was immediately apparent that the coupling was extremely high. By testing the issue from this perspective, I was able to gather concrete evidence.
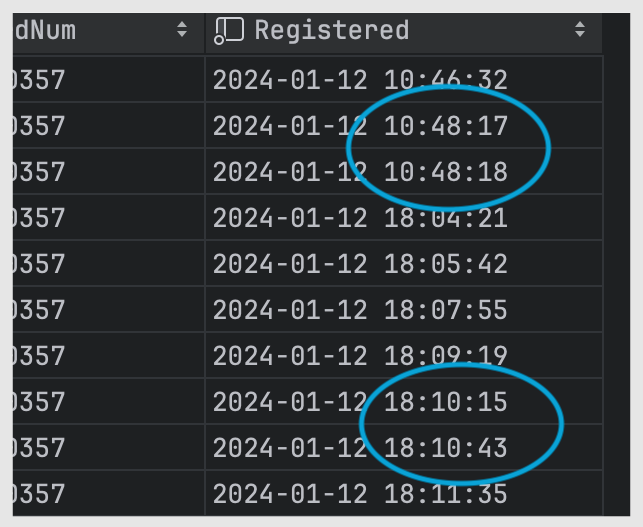
The time the data was saved in MySQL
In the first instance, the duplication occurred within one second, while in the second instance, it took about 30 seconds. This means the delay could potentially exceed 30 seconds. Such a delay does not occur on our internal network. It likely means the system is waiting for a response from an external source.
Next, I check the logs again.
[10:22:28.983][http-bio-8080-exec-7] INFO - ClientConnector.request() | request
[10:22:28.985][http-bio-8080-exec-7] INFO - ClientConnector.request() | response
[10:22:28.986][http-bio-8080-exec-7] INFO - ClientConnector.request() | endIn a successful scenario, the entire process—from the communication request to the response and connection termination—takes less than one second. However, the situation was different when duplicate keys occurred.
[10:23:25.832][http-bio-8080-exec-7] INFO - ClientConnector.request() | request
...
[10:23:38.863][http-bio-8080-exec-7] INFO - ClientConnector.request() | response
[10:23:38.865][http-bio-8080-exec-7] INFO - ClientConnector.request() | endIt took about 13 seconds to receive a response, and the connection was quickly terminated.
There were times when the wait was even longer.
[10:24:19.498][http-bio-8080-exec-7] INFO - ClientConnector.request() | request
[10:24:42.510][http-bio-8080-exec-4] DEBUG - AbstractHandlerMethodMapping...It takes about 30 seconds, and I can't see where the response has gone. It's processing a request from another thread.
We caught the culprit, but I still have some questions. If network latency caused by reliance on external services was the cause, why didn't it affect Redis?
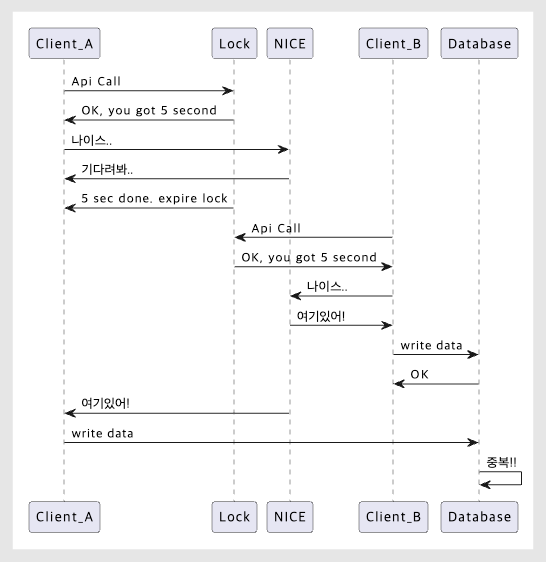
Duplicate communications
Previously, we set the expiration time for the Redis distributed lock to 5 seconds. So, as shown in the API flow above, if the response time from the external service exceeded 5 seconds (the default), the next request could acquire the lock even though the process hadn’t finished yet. From Redis’s perspective, this wasn’t a problem.
(You might be wondering why the table isn’t blocked. During the normalization process in the past, no separate keys were set on that table, so the table simply acts as a storage layer, saving data as it is received.)
Ultimately, the cause of the duplicate saves was unexpected (unforeseen) network delays caused by a part of the logic that was tightly coupled to an external API in a synchronous state. I really had to search high and low to find such a simple cause. 😂
Here's how we improved it!
There were several options worth trying. We could place a lock on the table where data is stored, or improve accuracy by implementing a system like Zookeeper. Alternatively, we could add a fencing token to Redis to perform additional consistency checks. We could also switch to an asynchronous calling method to reduce coupling. To sum it up we tried to improve the system by increasing the lock duration in Redis.
I narrowed down the options using the process of elimination! I wanted to avoid altering the table structure as much as possible, and introducing a new system would have required us to factor in the learning curve. Since this is a legacy project, it was difficult to gauge the scope of side effects that might result from changing how Redis operates. Additionally, because the business logic required immediate responses, switching to an asynchronous approach was also challenging.
Fortunately, this feature doesn’t generate excessive traffic. We were able to choose this option because we determined that increasing the lock time wouldn’t cause an overload. As a result, when we recently increased the lock time to the new standard, not a single duplicate occurred.
In closing
How did you find the troubleshooting process? In an era where there are so many convenient tools available, I found the solution by going back to the basics. From the emergence of various technologies to misguided suspicions and rational decisions, I think I’ve given you a glimpse into the joys and struggles of a developer’s life. Now that a month has passed since I joined the company, I feel a sense of pride knowing that I’ve been able to contribute, even in a small way, to the team and the organization.
It took some time because I was still unfamiliar with the service architecture, but thanks to my colleagues who worked with me, we were able to reach a conclusion. Troubleshooting in the real world isn’t much different; in the end, a battle of persistence. Thank you!
👉 Want to learn more aboutWadiz Backend Developers and Business Development Team? (Read the interview)
👉 Wadizis hiring Java backend developers!




