
출처 : Photo by Chris Liverani on Unsplash
안녕하세요. 와디즈 데이터플랫폼팀의 AI 엔지니어 입니다.
와디즈에서 작년에 도입한 시계열 분석 패키지인 ‘Prophet’을 소개하고, 이 패키지를 이용해 어떻게 월간 펀딩 금액을 예측하고 이용하고 있는지, 그 설명을 시작합니다.
기존 월간 펀딩 금액 예측 방법
크라우드펀딩 플랫폼인 와디즈에서는 실시간으로 펀딩과 관련된 많은 양의 데이터들이 생성, 누적되고 있습니다. 그중 가장 중요한 지표 중 하나가 아마 매출일 텐데요. 매출에 해당하는 지표인 펀딩 금액을 정확하게 예측하는 것이 회사의 실적을 평가하고 미래를 전망하는 데 필수 요소일 것입니다. 그렇기 때문에, Prophet 모델 도입 이전에도 비교적 간단한 방법을 사용하여 월간 펀딩 금액을 예측해 왔지요.
Prophet을 도입하기 전에는, ‘단순한 평균 기법’을 사용했어요. 예측 월의 1일부터 누적 일을 기준으로, 실제 일일 펀딩 금액의 평균을 통해 해당일의 펀딩 금액을 예측하는 방법입니다. 이 기법은 월초에는 오차가 크지만, 월말이 되면 차츰 자동보정이 되어 오차가 줄어들어요. 다만, 월말쯤이 되면 사실상 기법 적용이 필요 없을 정도로 누구나 다 예측 가능하다는 단점이 있습니다.
또 다른 단점은 2~3개월 뒤 오차가 매우 클 수 있다는 것이에요. 단순 평균으로 추정하다 보니 장기적인 관점에서 성장의 경향성이나 주간, 월간 시즌성의 반영이 전혀 되지 않습니다. 5~6개월 이후의 먼 미래에 대해 예측의 정확성이 무척 떨어질 수 밖에 없지요.
더 좋은 예측 방법을 찾아서
‘예측 모델 도입’은 기존 월간 펀딩 금액 예측 방법을 개선하고자 함에서 출발했습니다.
우선 전통적인 통계 기반의 ARIMA, SARIMA, ETS를 비롯하여 GRU, LSTM, DeepAR, Temporal Fusion Transformer 같은 최신 인공신경망 기반의 예측 모델을 테스트했습니다. 전통적인 통계 기반의 모델(ARIMA 등)은 로컬 모델로 장기간의 데이터를 학습하여 트렌드와 패턴을 파악하여 예측하는데 적당하지 않았어요. 인공신경망 기반의 모델의 경우는 아웃라이어나 노이즈에 쉽게 오버피팅되는 등 오히려 예측력이 떨어지는 것으로 확인되었고요.
Prophet는 긴 시계열에 대해서 잘 학습하고, 아웃라이어나 노이즈에도 강건하다고 알려져 있습니다. 가볍고, 학습 속도가 빠르면서도, 분석이 용이하다고 판단했어요.
그래서 Prophet을 도입하게 되었습니다.
Prophet
Prophet은 2017년에 Facebook(현 Meta)에서 Time-series를 다루기 위해서 만든 Library입니다. 통계적인 지식 없이 Time-series 데이터를 기반으로 자동으로 Forecast를 수행해주며, 아웃라이어, 데이터 부재 등에도 비교적 강건하게 모델링을 수행한다고 해요.
*참고 : 공식 홈페이지 Prophet
Facebook에서는 전문적인 시계열 분석가나 통계 전문가의 도움 없이 ‘도메인’ 전문가가 스스로 시계열 데이터를 분석하고 적용할 수 있도록 도구를 확보했어요. 기존의 통계 기반의 시계열 분석 모델인 ARIMA나 ETS, TBATS 등의 단점과 복잡성을 단순화한 모델을 개발하고 이를 Prophet으로 패키징하여 배포한 것이죠.
1. Prophet Model
모델은 아래와 같이 여러 컴포넌트로 구성되어 더하는 additive 모델입니다.
y(t)=g(t)+s(t)+h(t)+ϵt
간단하게 각 컴포넌트를 설명하면 다음과 같습니다.
- g(t)는 trend function으로, 시간의 변화에 따라 비주기성을 띠고 있는 변화를 모델링합니다. 구간별로 나누어진 Linear와 같은 선형 모형이나 Logistic과 같은 S자 모형으로 모델링합니다.
- s(t)는 주, 월, 연 단위의 주기성을 보이는 변화를 감지하고 모델링합니다.
- h(t)는 휴일/휴가, 비정기적인 사건과 같은 변화를 모델링합니다.
- ϵt은 모델링이 되지 않는 특이한 변화를 모델링합니다.
간단하게 말해, 앞에서 설명한 것과 같이 additive 모델로 위의 각 컴포넌트를 일반화하여 더하는 형태로 최종 y(t)를 산출합니다. (물론, 실제로는 더 복잡하지만요…😅)
2. Prophet 설치하기
- Linux에 설치하기
Linux에서는 아래의 코드로 설치를 진행합니다. pystan의 경우 특별한 버전과의 호환성으로 인해 해당 버전을 설치해야 한다고 해요. 다른 버전이 이미 설치된 경우, 가상 환경을 구성하고 설치하거나 새로 설치한 후에 prophet 설치를 진행하는 것이 좋을 듯합니다.
$ pip install pystan==2.19.1.1
$ pip install prophet
- Mac에 설치하기
Mac에 설치하는 것은 Linux 설치와 동일하지만, stan 패키지 설치와 관련한 아래와 같은 에러가 발생하는 경우도 있습니다.
Failed to build prophet
Installing collected packages: pymeeus, korean-lunar-calendar, hijri-converter, ephem, convertdate, setuptools-git, pystan, LunarCalendar, holidays, cmdstanpy, prophet
Running setup.py install for prophet ... error
ERROR: Command errored out with exit status 1:
command: /Users/taekgoo.kim/opt/anaconda3/bin/python -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/private/var/folders/8r/4wg9cnks1pbcy18k8h0q31kd30ljx5/T/pip-install-y53ha47p/prophet_c75b6208bc884daba052e08f6a385f14/setup.py'"'"'; __file__='"'"'/private/var/folders/8r/4wg9cnks1pbcy18k8h0q31kd30ljx5/T/pip-install-y53ha47p/prophet_c75b6208bc884daba052e08f6a385f14/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /private/var/folders/8r/4wg9cnks1pbcy18k8h0q31kd30ljx5/T/pip-record-rduv76rs/install-record.txt --single-version-externally-managed --compile --install-headers /Users/taekgoo.kim/opt/anaconda3/include/python3.8/prophet
cwd: /private/var/folders/8r/4wg9cnks1pbcy18k8h0q31kd30ljx5/T/pip-install-y53ha47p/prophet_c75b6208bc884daba052e08f6a385f14/
Complete output (10 lines):
running install
running build
running build_py
creating build
creating build/lib
creating build/lib/prophet
creating build/lib/prophet/stan_model
Importing plotly failed. Interactive plots will not work.
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_dfdaf2b8ece8a02eb11f050ec701c0ec NOW.
error: command 'gcc' failed with exit status 1
이런 오류를 보는 경우, 아래의 조치한 후 다시 설치를 진행하면 됩니다.
$ xcode-select --install
$ pip install pystan==2.19.1.1
$ pip install prophet
3. Prophet 기능
Prophet의 주요 기능은 다음과 같습니다.
- Saturating Forecast (포화도 예측): 성장 또는 감소의 최대치 또는 최소치를 설정하여 포화도를 예측할 수 있습니다. 포화도는 와디즈를 예로 들자면, 성장할 수 있는 최대 예상치를 의미해요. 시장의 크기나 규제 등으로 인한 제약 가능성을 반영하여 예측할 수 있습니다.
- Trend Changepoints (경향 변경점): 상승 또는 감소의 경향이 변경되는 지점을 자동으로 판단하고 구분할 수 있습니다. 실제로 Prophet을 학습한 후 간단하게 1~2줄만의 코드로 Trend Chagepoints를 확인해볼 수 있어요.
- Seasonality, Holiday Effects, and Regressors (계절 변동성, 휴일 효과, 회귀 요소): 계절에 따른 변화나, 휴일 또는 주말과 같은 효과를 포함하여 예측을 진행할 수 있어요. 별도의 요소(Regressor)를 추가하여 예측에 자동으로 활용할 수도 있습니다.
- Multiplicative Seasonality (곱셈 계절성): 계절성은 기본적으로 additive (뎃셈)의 형태로 피팅되지만, 계절성을 곱하기(Multiplicative)로 피팅 되어 예측에 활용될 수 있습니다. 이런 경우 시간이 지남에 따라 진폭이 커지는 예측을 하게 됩니다.
- Uncertainty Intervals (불확실성 구간): 경향성, 계절성 또는 추가적인 노이즈에 대해 불확실성 구간을 판단하여 yhat 변수에 포함하여 출력해줍니다.
- Outliers (아웃라이어처리): Outlier를 NA처리하면 자동으로 Interpolation을 수행하여 outlier를 제거/다룰 수 있도록 해줍니다.
- Non-Daily Data: 시간 단위의 데이터나 월간 단위, 또는 특정한 기간 단위의 데이터를 다룰 수 있습니다.
- Diagnostics (모델 진단): 모델에 대한 Cross-Validation이나 Parameter Tuning을 지원해줍니다. 와디즈에서도 이 기능을 활용하여 Cross-Validation과 Parameter Tuning을 수행했어요. 현재 최선의 결과를 찾아서 배포 및 운용 중입니다.
학습용 데이터 수집하기
데이터를 수집한 이후, 주요 기능을 활용하여 모델링 하기 전 모델에 학습하기 위한 데이터를 수집하고 분석했습니다.
와디즈는 기존의 e-commerce와는 성격이 다른 플랫폼이에요. 따라서 펀딩 금액 예측에 필요한 데이터의 유형이나 형태도 다릅니다. 이점을 유념하면서, 펀딩 전체 금액에 영향을 줄 수 있는 인자는 어떤 Feature일까 고민하면서 데이터를 수집했습니다.
이미 와디즈 내부에는 활약하고 있는 여러 데이터 분석가, 데이터 엔지니어, 머신러닝 엔지니어들이 있습니다. 덕분에 고민의 시간을 줄일 수 있었어요.
내부 Database에서 매일 수집하고 있는 지표 중 약 140여 개 정도의 Feature를 선정했습니다. 자체적인 분석과 내부 동료들의 조언에 따라 우선 펀딩 프로젝트와 연관성이 높은 Feature를 선정했지요. 이 과정에서 140개의 데이터 중 일부만을 활용하게 되었어요. 펀딩 프로젝트와 연관성인 낮은 데이터, NA 비율이 높거나 노이즈 많은 데이터는 제외했습니다.
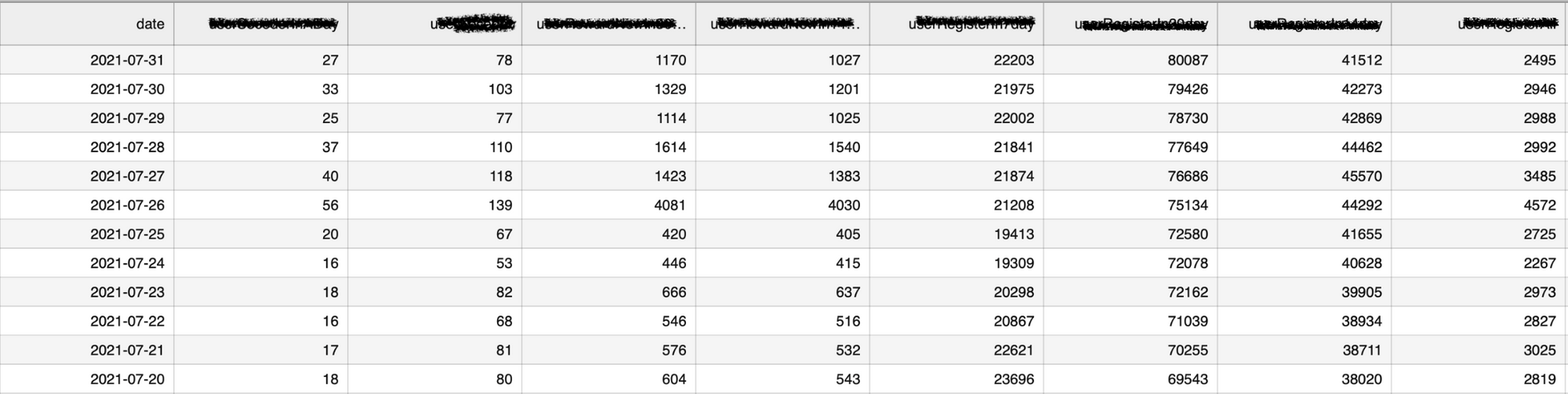
학습 전 데이터 특성 분석을 위한 데이터 수집의 크기와 Feature는 다음과 같습니다.
- 데이터 수집 범위: 2017-01-01~2021-07-31
- Feature: 펀딩 금액과 연관도가 높다고 보이는 25개 Feature. 아래는 그중 일부 Feature입니다.
- 일 단위 펀딩 금액
- 일 단위 펀딩 참여 수
- 일 단위 펀딩 취소 금액
- 일 단위 좋아요 수
- 일 단위 지지서명 수
- 일 단위 알림요청 수
- DAU: 일 단위 액티브 사용자 수
- MAU: 월 단위 액티브 사용자 수
- 일 단위 프로젝트 종료 수
- 현재 진행 중인 프로젝트 수
- 일 단위 프로젝트 개설 수
- 일 단위 프로젝트 심사 수
- 일 단위 성공 프로젝트 수
- 회원가입 수
- (생략)
전체 140개 Feature 중에서 위 데이터를 포함한 25개 정도의 Feature를 우선 선정하여 수집하고 분석하기 시작했습니다.
데이터 탐색
1. Heatmap 분석
데이터 분석 중 가장 간단하면서도 다양한 Feature 간의 연관성을 볼 수 있는 Heatmap을 살펴봅시다.
아래와 같이 Seaborn 패키지의 Heatmap Chart를 이용하여 Feature 사이의 연관성을 추출했어요.
오른쪽의 Red-Yellow-Green 그라데이션은 각 Feature가 연관 정도를 보여줍니다. 붉은색일수록 낮은 연관도이며, 초록색이 진해질수록 높은 연관도를 보여주는 직관성을 보여주고 있습니다.
X축과 Y축은 Feature로 이 Heatmap에서 대각선은 자신의 연관성을 의미해요. 따라서, 아래 그림과 같이 대각선은 ‘1’의 연관도를 보여주고 있습니다.
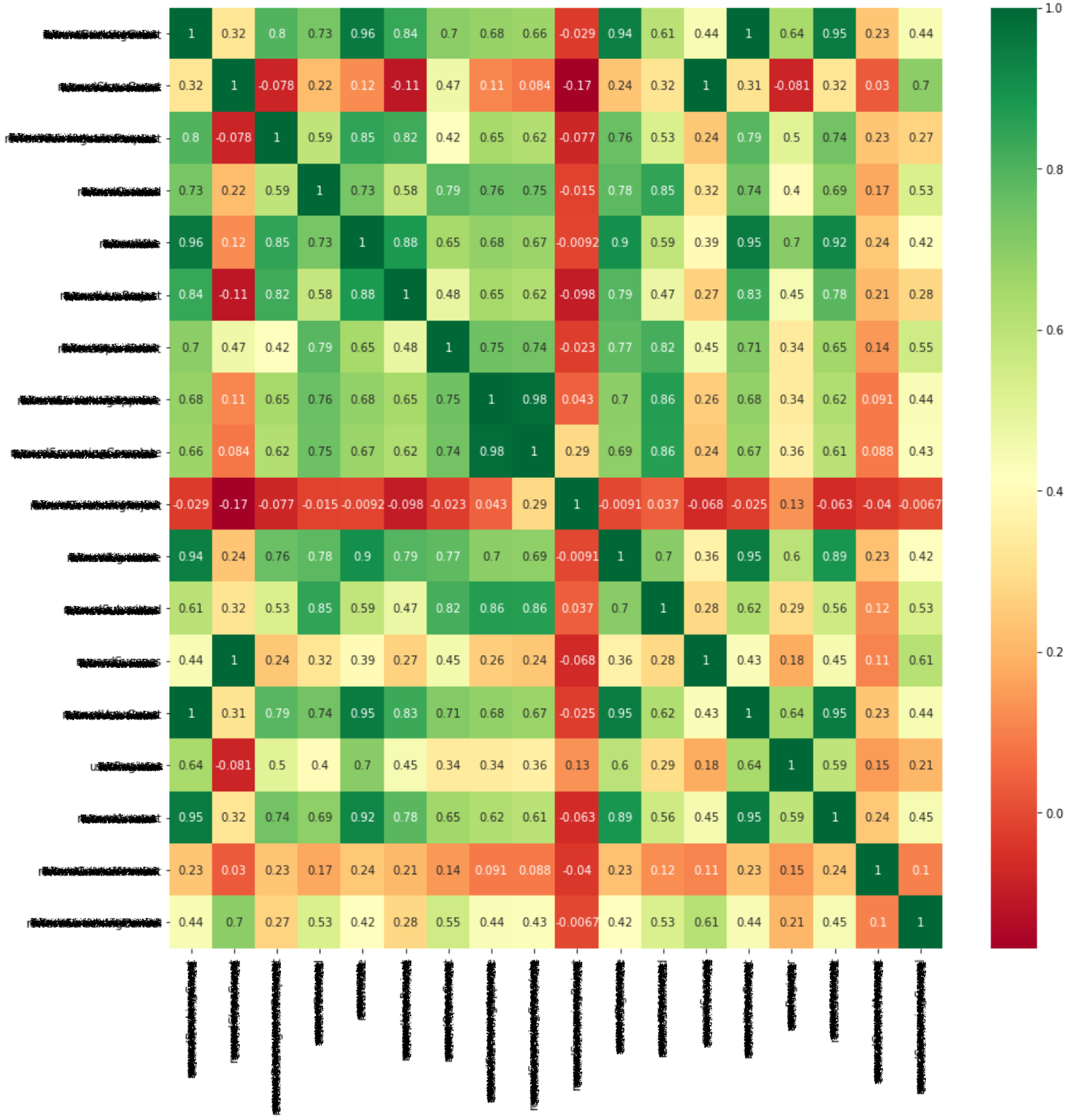
위 테이블 중 예측 목표인 펀딩 금액과의 연관도만 우선 순위화하여 일부를 테이블화 해보았어요.
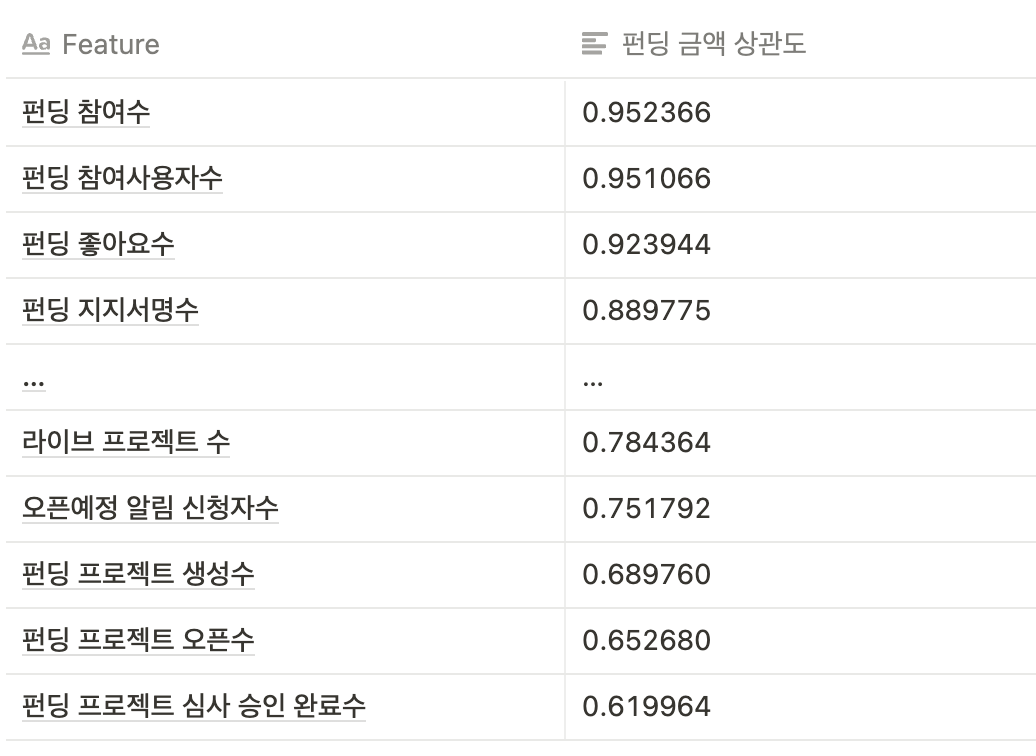
실제 위의 테이블에서 ‘펀딩 참여 수’와 ‘펀딩 참여사용자 수’는 펀딩 금액과의 상관도가 높습니다. 그러나 서포터의 펀딩 참여 행위가 금액을 일으키는 지표이기 때문에 분석이나 학습 시 제외(상당히 높은 co-linearity)해야 하지요.
특히, 선형 모델의 경우에는 펀딩 금액, 펀딩 참여 수, 펀딩 참여사용자 수와 같이 사실상 동일 지표를 중복해 사용한다면, 특정 특성(Feature)이 과대하게 반영되어서 모델의 성능이 오히려 떨어질 수 있게 됩니다.
2. Feature Importance
Scikit-Learn 패키지의 Tree Model을 활용하여 Feature Importance를 측정해 보았습니다.
Feature Importance는 Tree Model이 Tree Node를 생성할 때, 어떤 Feature를 우선으로 해야 분류가 깔끔(?)하게 되는지를 기준으로 일명 ‘모델이 생각하는 Feature 우선순위’입니다.
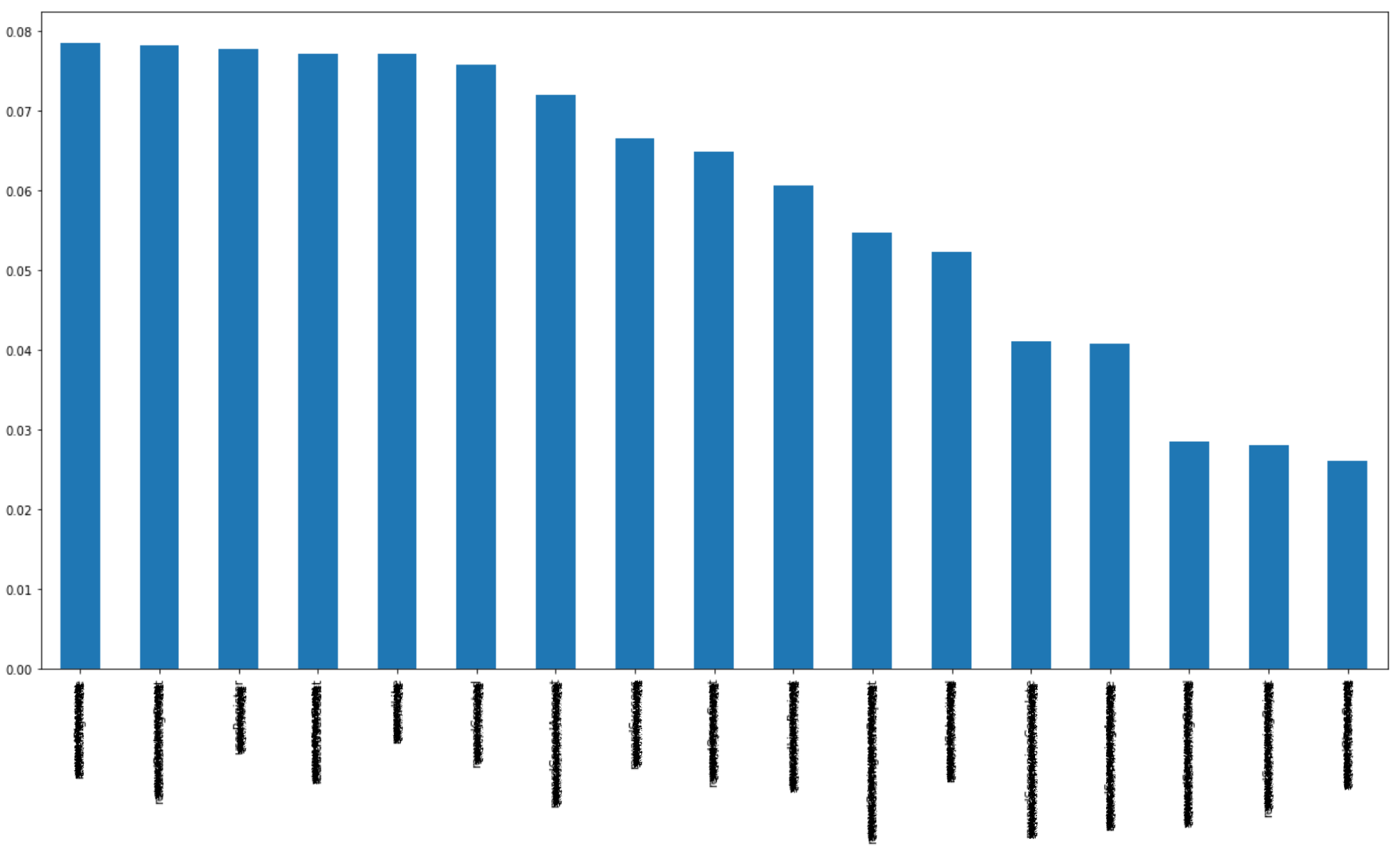
주요 Feature 별 중요도는 아래 테이블과 같습니다.
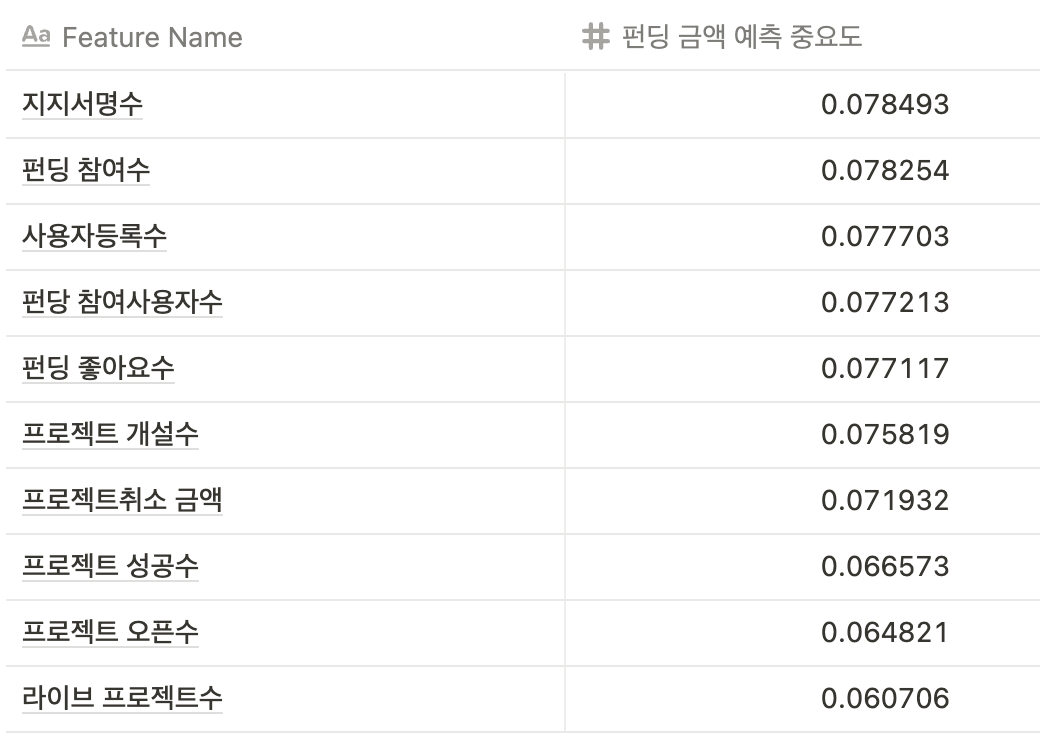
펀딩 금액 상관도와 모델의 예측 중요도가 다름을 확인할 수 있어요. 하지만, 이 데이터는 실제 학습에 활용할 데이터를 선정하기 위한 일종의 탐색 과정입니다. 모두를 활용할 것은 아니지요.
실제로 펀딩 금액 데이터는 시계열 데이터로 단편적으로 다른 Feature와의 상관도나 Importance와는 관계없이 자체의 패턴이나 외부 요인들(휴일, 날씨 등)의 영향을 받을 수도 있습니다. 또한, 시간의 변화와 관련된 데이터는 위 분석 방법에서는 나타나지 않는다고 볼 수 있고요.
학습을 위한 데이터 선정
학습데이터는 위에서 선정한 데이터 25개 중에서, 상관도와 중요도에서 펀딩 금액과의 공선성(Co-linearity)이 높다고 보이는 ‘펀딩 참여사용자 수’, ‘펀딩 참여 수’ 등은 제외했어요. 상위 5개 항목 중 중복되는 4개 Feature를 우선 선정했습니다.
- 라이브 프로젝트 수
- 오픈예정 알림 신청자 수
- 펀딩 좋아요 수
- 펀딩 지지서명 수
그다음, 이 학습 데이터를 활용하여 본격적인 모델 구축을 진행했습니다.
Prophet을 활용한 시계열 예측 모델 만들기
1. 펀딩 금액만으로 간단한 시계열 예측 모델 만들기
우선은 펀딩 금액 자체의 시간 변화에 따른 패턴이나 경향성만으로 예측 모델을 만들 수 있는지 시도해보았어요.
모델 평가 지표
모델의 평가지표는 평균 절대 오차율(mean absolute precentage error 또는 mape)을 주로 사용하여 부가 지표로 평균 절대 오차(mean absolute error 또는 mae)를 사용했습니다.
데이터 임포트 및 학습하기
2017년 1월 1일부터 2021년 6월 30일까지의 데이터를 데이터 프레임화하고, 마지막 한 달의 기간을 백 테스트 용도로 분리해두었어요. Prophet의 기본 파라미터를 사용하려 학습 및 베이스라인을 잡기 위한 평가를 진행했습니다.
from prophet import Prophet
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error
df = pd.read_csv('../data/KPIDay.20170101.20210630.train.csv', index_col=0)
train_df = df.head(-30)
m = Prophet(seasonality_mode='additive')
m.fit(train_df)
예측할 데이터 프레임 만들기 및 예측하기
간단하게 아래와 같이 몇 줄만으로 예측을 실행할 수 있어요.
future_df에는 과거를 포함하여 예측할 미래의 date를 포함하여 데이터 프레임을 만들어 놓습니다. 그러면, 이를 기반으로 자동으로 예측값을 생성하여 forecast라는 데이터프레임으로 출력해줍니다.
future_df = df.copy()
future_df.rename(columns={'date':'ds'},inplace=True)
forecast = m.predict(future_df)
학습/예측 결과 Plotting 하기
위에서 학습한 모델 m으로 아래와 같이 pre-define 된 차트를 그릴 수 있어요.
fig1 = m.plot(forecast, figsize=(20,10), xlabel='year-month', ylabel='reward amount')
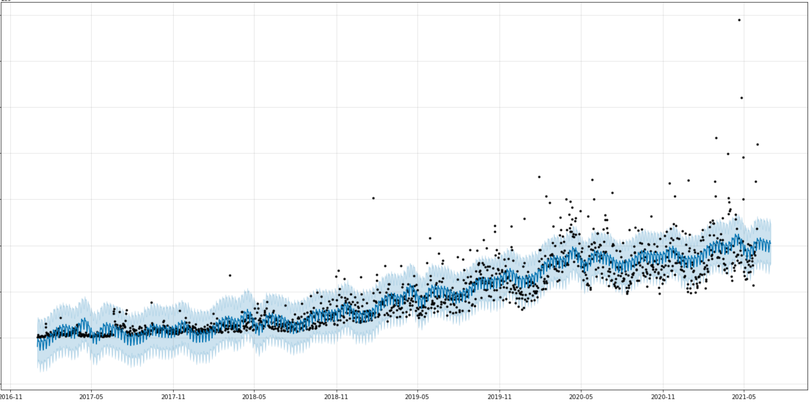
x축은 펀딩 금액, y축은 연-월이며 검은색 점이 실제 데이터 포인트입니다. 파란색 실선은 모델의 예측값이에요. 상승곡선과 상승/하락의 패턴을 잘 포착해 보여주고 있습니다. 하늘색 영역은 하위 10%와 상위 90%로 불확실성 예측(Uncertainty)의 범위를 보여주고 있고요.
위 차트에서 오른쪽 2021-06부분은 실제 데이터 포인트인 검은색이 없지만, 패턴에 따라 예측을 수행한 것을 볼 수 있습니다.
또한, 모델의 각 컴포넌트 (g(t), s(t))도 아래와 같이 간단하게 Plotting 할 수 있습니다.
fig2 = m.plot_components(forecast, figsize=(20,20))
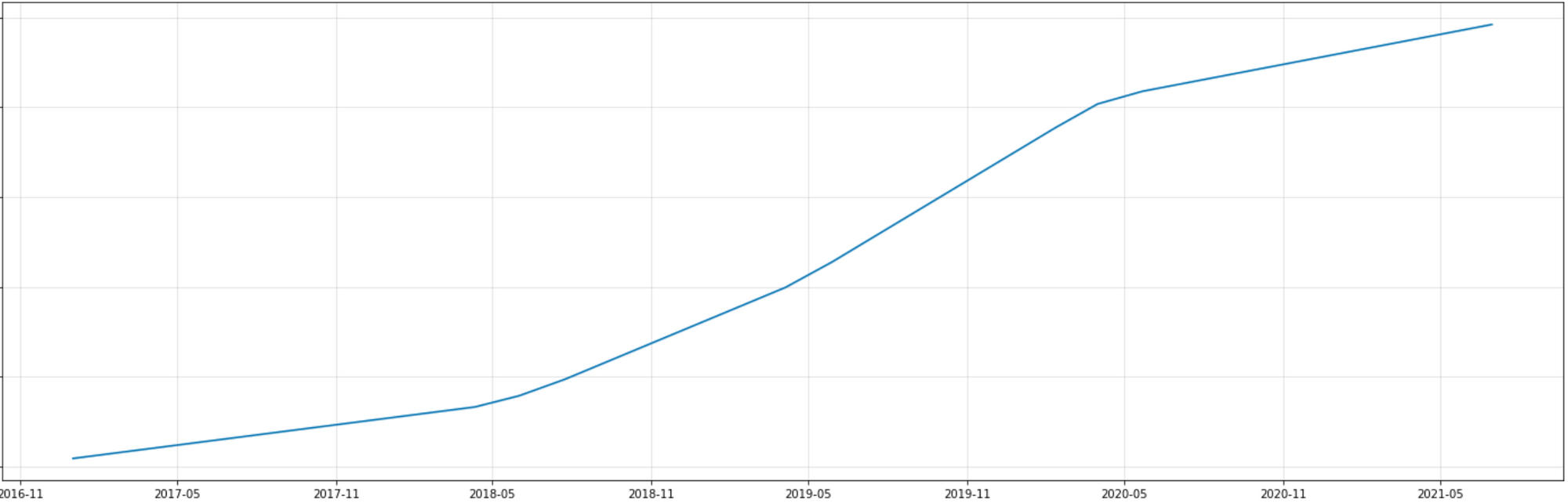
Trend
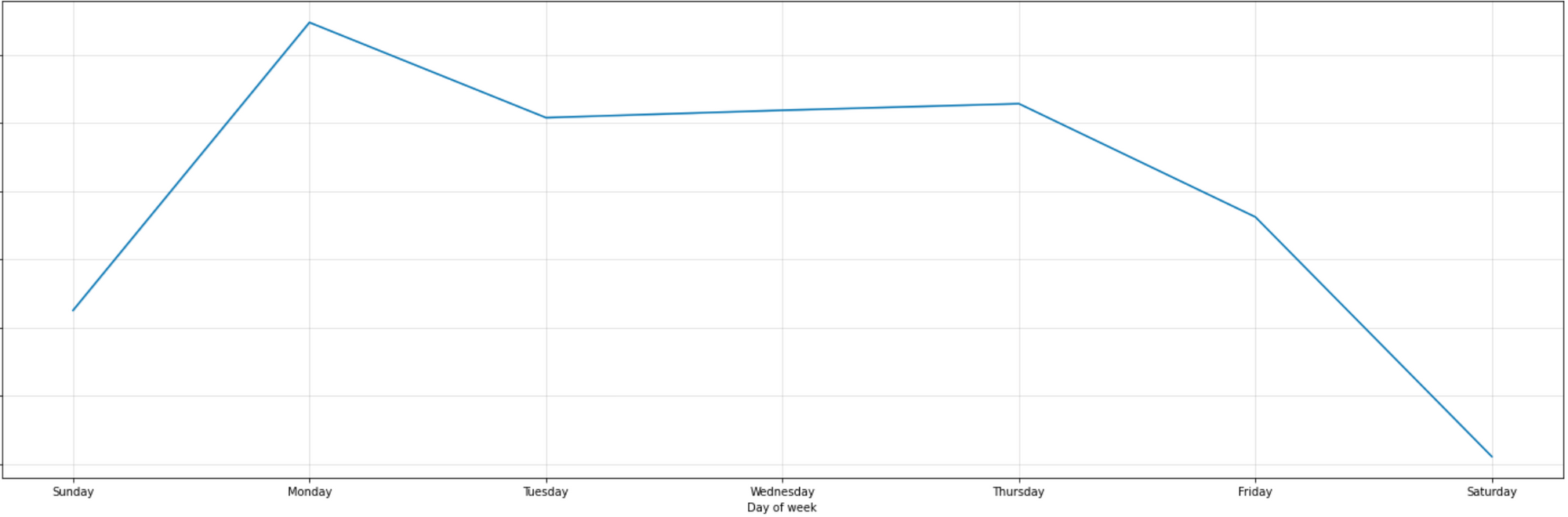
Weekly Pattern
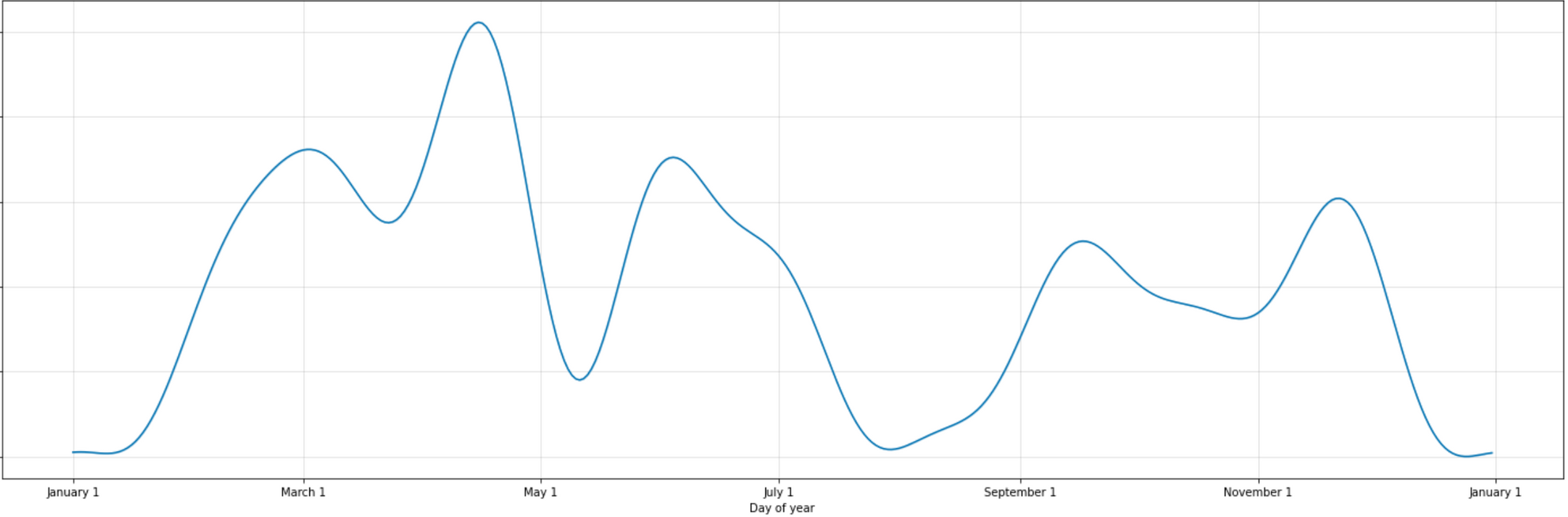
Yearly Pattern
위 차트에 대해서 간단하게 해석해보자면,
- 펀딩 금액의 Trend는 계속 증가하고 있으며, 다른 때보다 2018-05~2020-05구간에서 특히 성장이 두드러집니다.
- 주간 패턴은 월요일에서 펀딩 금액이 가장 높고, 주중에 유지되다가 주말에 가장 낮은 경향을 보입니다.
- 연간 패턴은 봄(3~4월)에 펀딩 금액이 가장 크고, 여름철(7~8월) 구간과 겨울철(1월)이 가장 낮은 경향을 보입니다. 묘하게 휴가나 방학 시즌과 겹치는 것을 볼 수 있지요.
위 패턴은 언제나 동일한 것이 아니라, 데이터 범위(기간의 변경이나 추가 데이터)나 모델의 파라미터에 따라 달라질 수 있음을 유념해야 해요.
순수하게 예측의 대상인 펀딩 금액으로만 모델링을 하였고, 모델의 기본 파라미터로 학습한 결과입니다.
2. 다른 Feature를 추가하여 시계열 예측 모델 만들기
다음으로는 Feature를 추가할 경우, 이것이 성능에 어떤 영향을 미치는지, 모델의 파라미터 변화에 따라 어떤 영향이 있는지 살펴봅시다. Prophet에서 제공하는 Grid Search 기능을 활용하여 진행하였습니다.
이전, 데이터 분석을 통해 펀딩 금액과의 연관성이나 중요도를 고려한 4가지 Feature를 선정하였는데요. 이 Feature을 활용하여 모델을 만들어보겠습니다.
간략히 소개하자면, 우선은 모델의 파라미터를 튜닝한 후, Feature 조합을 실험하여 최적화를 진행했습니다.
2-1. Grid Search로 모델 파라미터 최적화
모델 파라미터 최적화를 위해서 Prophet 제작자들이 추천하는 파라미터의 튜닝 범위를 Grid Search 방식으로 조합하여 적용하였습니다. 사실 파라미터의 의미를 이해하기 쉽지 않은데, Grid Search를 활용하면 적절한 파라미터를 찾는 데 큰 도움이 됩니다.
Search Space 정의
Tuning 가능한 Hyperparameter는 아래 Prophet 공식 페이지에서 가이드하는 것을 참고했습니다.
* 참고 : Diagnostics
- changepoint_prior_scale: chagepoint는 trend의 변화하는 크기를 반영하는 정도로 가장 효과가 크다고 말하는 파라미터입니다. 기본값은 0.05, 제작자들은 0.001~0.5 사이가 적당하다고 합니다. Log 단위로 Tuning을 하는 것을 추천합니다.
- seasonality_prior_scale: 계절성을 반영하는 단위로 기본값은 10이며, 0.01 ~ 10 사이가 적당하다고 합니다.
- holidays_prior_scale: 공휴일 효과를 반영하는 단위로 기본값은 10이며, 0.01 ~ 10 사이가 적당하다고 합니다.
- seasonality_mode: additive 또는 multiplicative 중에 하나를 선택하여 계절성으로 나타나는 효과를 더할지 곱할지 정하는 것입니다. 기본값은 additive이며, multiplicative로 선택하면 시간이 지남에 따라 진폭이 커지게 됩니다.
- holidays: 한국의 공휴일 정보를 담은 dataframe
참고로, 공휴일 정보를 담은 데이터 프레임은 아래의 코드로 생성할 수 있습니다.
import holidays
# 필요한 날짜만큼 생성
date_list = pd.date_range('2017-01-01', '2021-12-31')
# 한국 휴일 객체 생성
kr_holidays = holidays.KR()
# generate holiday table
holiday_df = pd.DataFrame(columns=['ds','holiday'])
holiday_df['ds'] = sorted(date_list)
holiday_df['holiday'] = holiday_df.ds.apply(lambda x: kr_holidays.get(x) if x in kr_holidays else 'non-holiday')
공휴일 정보를 포함하여 Search Space를 아래와 같이 정의합니다.
search_space = {
'changepoint_prior_scale': [0.05, 0.1, 0.5, 1.0, 5.0, 10.0],
'seasonality_prior_scale': [0.05, 0.1, 1.0, 10.0],
'holidays_prior_scale': [0.05, 0.1, 1.0, 10.0],
'seasonality_mode': ['additive', 'multiplicative'],
'holidays': [holiday_df]
}
Grid Search 조합 및 수행
위에서 정의한 search_space에 따라 모든 조합을 발생하면 전체 192개의 조합이 나오며, 192개의 서로 다른 Hyperparameter로 아래의 프로세스에 따라 학습을 수행했습니다.
- 발생한 모든 조합을 cross_validation 진행
- initial: 최소 2년(20170101)을 학습 진행 후
- period: 매 90일 단위로
- horizon: 30일에 대한 평가
- cross_validation 수행 후 performance metric(mape; mean absolute percentage error)을 산출하여 tuning_results에 저장
- 일일 예측값과 실제값과 오차율
전체 수행 결과를 기록하고 가장 좋은 Hyperparameter 조합을 기록하여 사용했어요.
param_combined = [dict(zip(search_space.keys(), v)) for v in itertools.product(*search_space.values())]
mapes = []
for param in param_combined:
print('params', param)
_m = Prophet(**param)
if regressors is not None:
for regressor in regressors:
_m.add_regressor(regressor)
_m.fit(train_df)
_cv_df = cross_validation(_m, initial='730 days', period='90 days', horizon='30 days', parallel='processes')
_df_p = performance_metrics(_cv_df, rolling_window=1)
mapes.append(_df_p['mape'].values[0])
tuning_results = pd.DataFrame(param_combined)
tuning_results['mapes'] = mapes
Prophet이 빠르고 가볍지만, 전체 192개의 조합에서 최적값을 찾는 데는 꼬박 하루 이상이 소요되었습니다. 그 결과는 아래와 같습니다.
Grid Search 수행 결과
Grid Search 수행 결과는 다음과 같이 정리할 수 있습니다.
- 최상의 조합은
- changepoint_prior_scale: 0.5, seasonality_prior_scale: 0.05, holidays_prior_scale: 0.05, seasonality_mode: additive
- mape min/max: 0.1237 ~ 0.18
- 평균: 0.14
- 표준편차: 0.01
- mape 0.16 이상의 특이치 몇 개를 제외하고는 표준편차가 작은 것으로 보아 hyperparameter에 크게 민감한 것은 아니며, 좋지 않은 mape 결과를 낸 조합만 피하면 될 것으로 판단했어요.
- changepoint_prior_scale = 0.5 또는 0.05과 seasonality_mode = additive로 유지되면 metric 상 큰 demerit은 보이지 않았습니다.
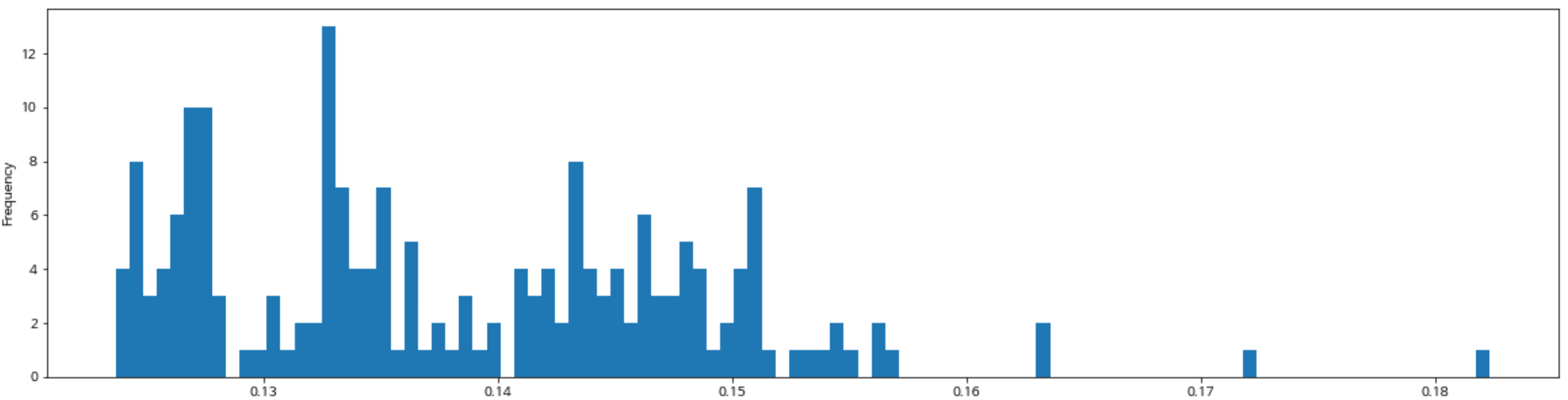
아래 차트는 모델의 성능(mape)별 histogram입니다. 주로 0.12 ~ 0.15에 모여있음을 볼 수 있습니다.
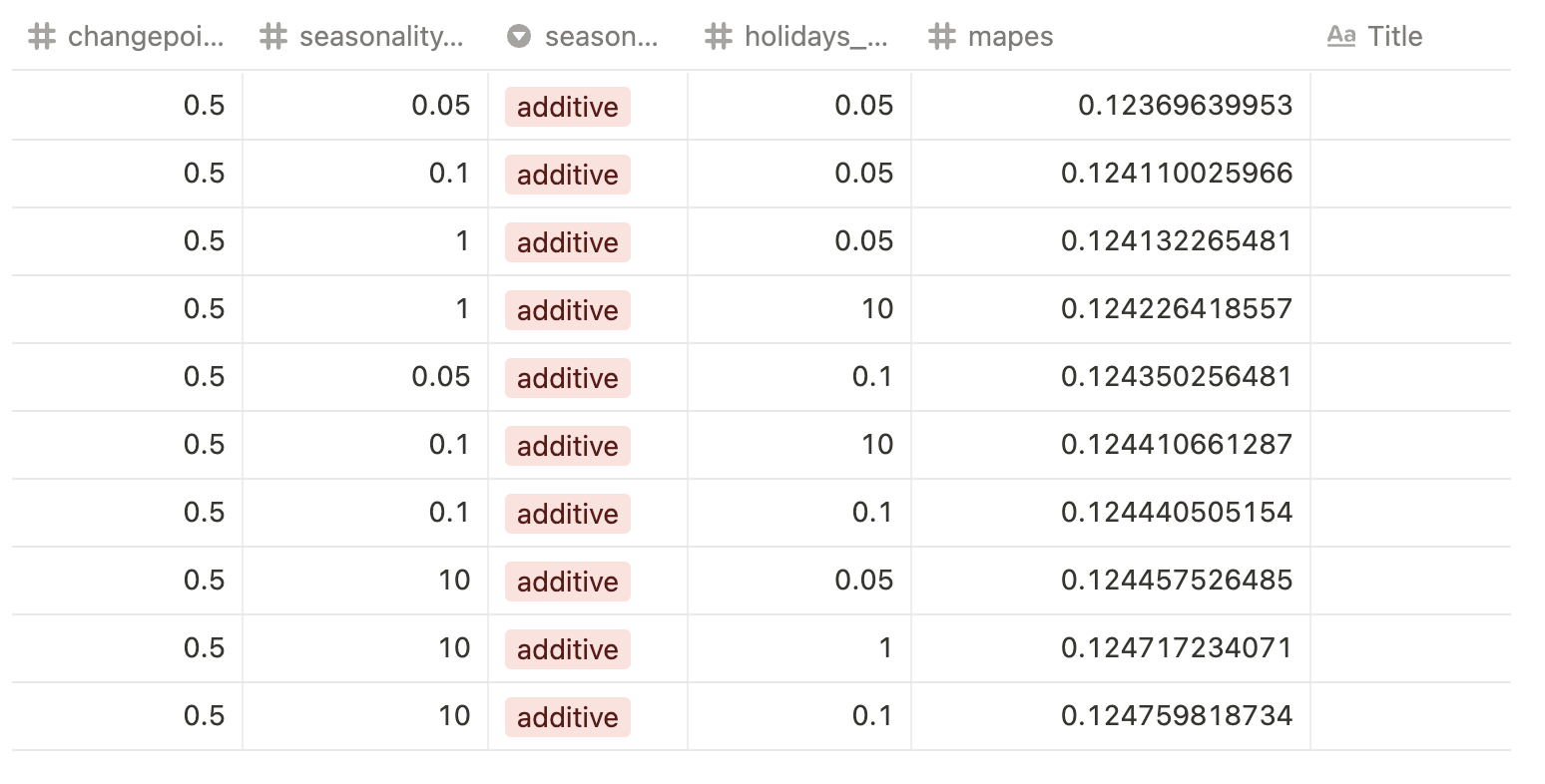
아래 테이블은 학습한 192개 모델 중 가장 좋은 성능을 보인 상위 10 모델의 파라미터 조합이에요. 테이블에서 보는 것과 같이 changepoint_prior_scale와 seasonality_mode가 가장 영향력이 큰 것으로 보입니다. 다른 파라미터는 상대적으로 영향이 작은 것으로 보이고요.
2-2. 펀딩 금액 외 추가 Feature를 사용한 모델 튜닝
Prophet에서는 추가적인 Feature를 사용하여 예측하는 것을 Regressor라고 정의했어요. 여기서는 앞에서 데이터 분석을 통해 뽑아 놓은 4개의 연관 Feature를 사용했습니다.
Regressor 조합 정의
아래의 추가 Feature를 조합하여 regressor 조합 실험을 진행하였습니다.
- RewardLike: 펀딩 좋아요 수
- RewardSignature: 펀딩 지지서명 수
- RewardLiveProject: 라이브 프로젝트 수
- RewardComingsoonRequest: 오픈예정알림 신청 수
위 feature 목록을 조합해 가장 좋은 조합을 찾기 위해 실험했습니다. 아래 코드를 통해서 생성했으며, 모델의 파라미터는 앞에서 진행한 실험을 통해서 찾은 최적의 파라미터를 적용했습니다.
또한 기간별 8개의 백 테스트를 수행하여 모델의 변동성이나 안정적인 예측 능력을 평가했어요.
regressors = ['rewardLike', 'rewardSignature', 'rewardLiveProject', 'rewardComingsoonRequest']
regressors_list = []
for L in range(0, len(regressors)+1):
for subset in itertools.combinations(regressors, L):
regressors_list.append(list(subset))
Regressor 조합 실험 결과
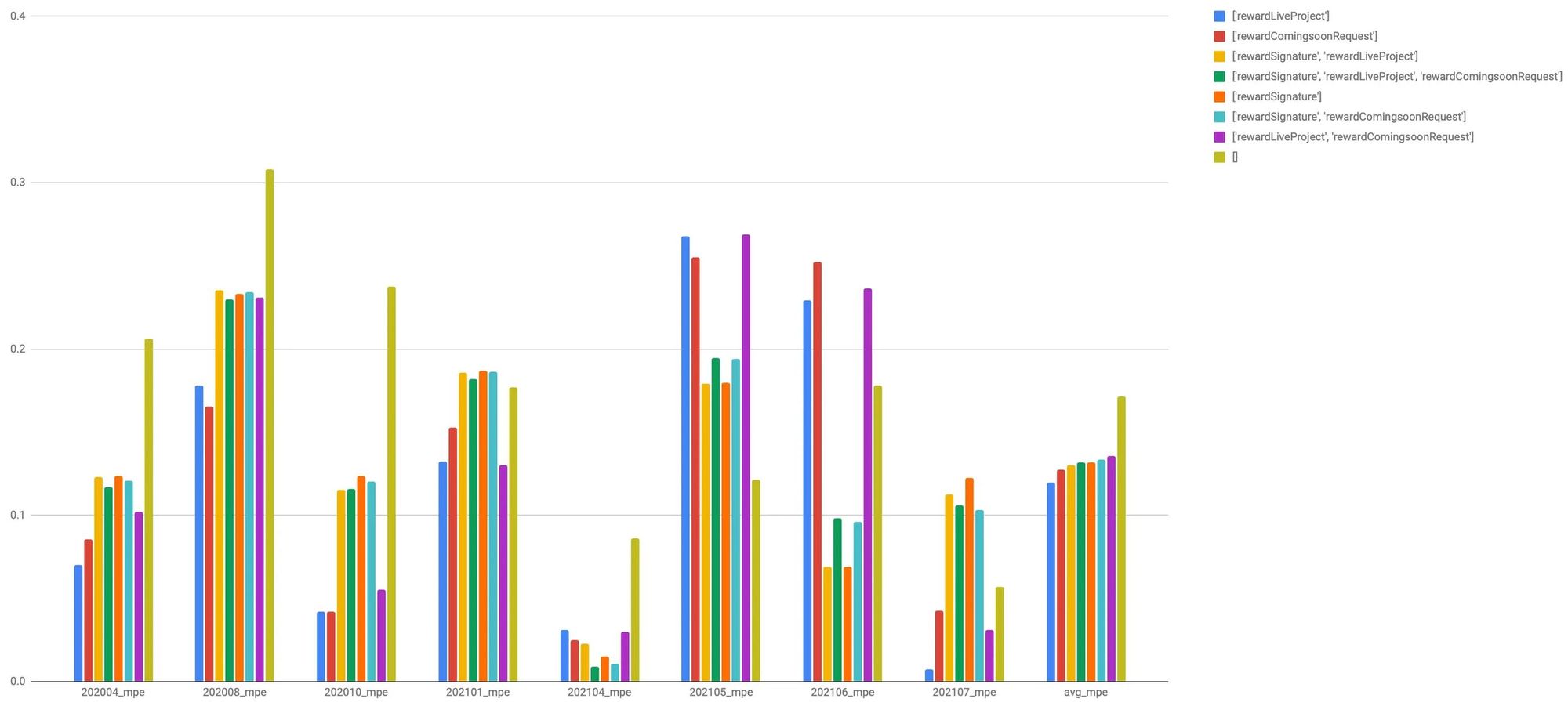
- ‘라이브 프로젝트 수’만을 Regressor로 사용한 예측 모델이 가장 좋은 평균 mape를 보여주었습니다.
- ‘라이브 프로젝트 수’를 사용한 Model의 경우 8번의 BackTest에서 평균 성능은 우수하지만, 편차가 다소 있는 것으로 보였습니다. 즉 예측을 잘하는 경우와 못하는 경우의 간극이 크다고 볼 수 있어요.
- 다만, ‘펀딩 지지서명 수’와 ‘라이브 프로젝트’를 조합한 모델의 경우 평균 mape 성능은 다소 떨어지지만 편차는 가장 적었습니다. 즉, 예측을 잘하는 경우와 못하는 경우의 간극이 적고 변화에 잘 대응한다고 생각할 수 있습니다.
아래 차트는 조합별 모델의 성능(mape)을 시각화한 것이에요. 튜닝 전의 가장 간단한 모델(올리브색)보다 Regressor를 조합하였을 때, 상당한 성능 향상이 이루어진 것을 확인할 수 있습니다.
최종 모델 조합 정리
위 2개의 개별적인 실험을 통해서
- Hyperparameter는 changepoint_prior_scale: 0.5, seasonality_prior_scale: 0.05, holidays_prior_scale: 0.05, seasonality_mode: additive로 정의하고,
- Regressor는 ‘펀딩 지지서명 수’와 ‘라이브 프로젝트’를 추가
하여 배포를 위한 구축을 진행했습니다.
Prophet 모델의 특성상 추가적인 Regressor는 미리 학습과 예측을 수행한 후 이 값을 ‘펀딩 금액 예측’ 모델의 입력값(Regressor)으로 비로소 활용할 수 있어요. 예측값을 다른 학습의 입력값으로 사용할 때는 오차가 전파(propagation)되는 것을 주의해야 합니다. 오차가 전파되는 경우 최종 예측하려는 ‘펀딩 금액 예측’ 모델의 오차를 많이 증가시킬 수 있기 때문이에요.
‘펀딩 지지서명 수’와 ‘라이브 프로젝트 수’는 펀딩 금액보다 예측범위가 작고, 오차율이 상대적으로 작아서 학습에 사용할 수 있다고 확인하여 활용했습니다.
모델 배치
모델 최적화를 통해 모델의 오차율이 8회 백 테스트 기준 평균 11%정도인 것을 확인했어요. 실무 적용이 가능하다고 판단해 모델을 배치하여 운용하게 되었습니다. 간단하게 구축한 아키텍처와 흐름을 소개합니다.
아키텍처 소개
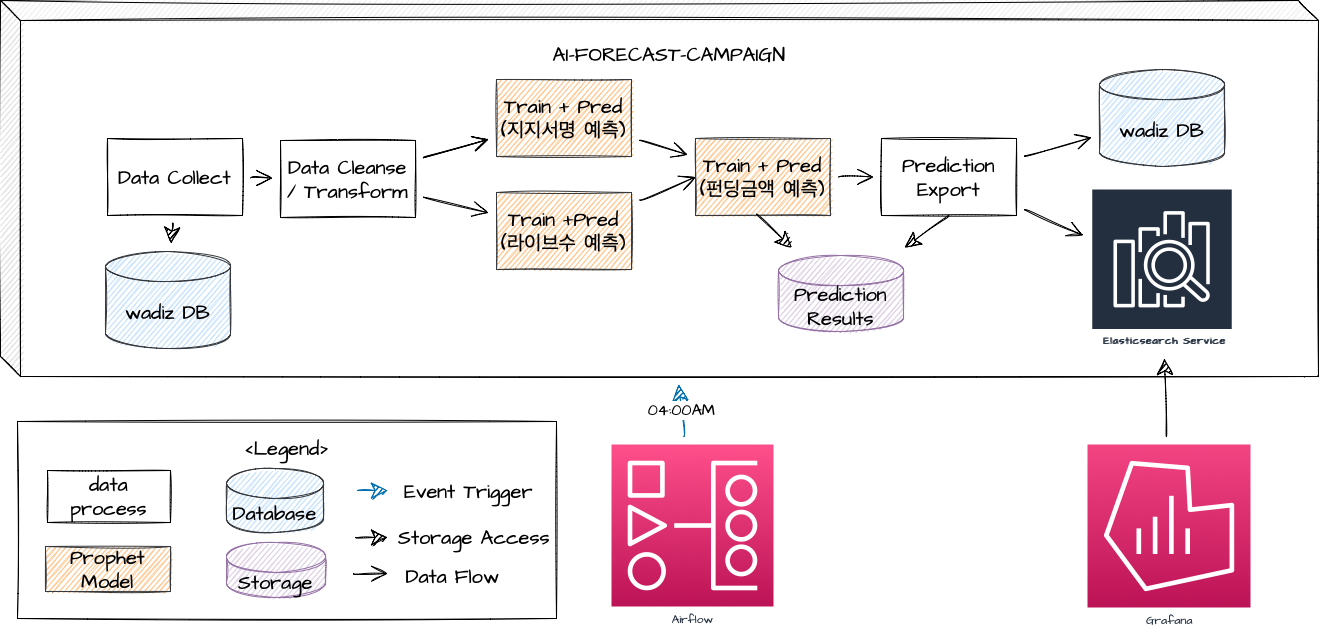
Prophet의 간단하고 빠른 학습 덕분에 매일 4시에 전날 데이터를 수집하고, 데이터를 클린징/변형하여 3개의 구조적 모델링을 진행합니다. 대략적인 흐름은 아래와 같습니다.
- 매일 4시 Apache AirFlow가 AI-Forecast-Campaign을 Trigger 합니다.
- 데이터 수집기가 wadiz DB에서 학습에 필요한 신규 데이터를 수집하고, 이 데이터는 학습에 필요한 형태로 정제/가공됩니다.
- 지지서명 예측 모델: 3년 전부터 전날까지의 ‘지지서명 수’ 데이터로 학습하여, 미래 1년의 지지서명 수를 예측하는 모델입니다. 이 모델의 출력값은 펀딩 금액 예측 모델의 입력값이 됩니다.
- 라이브 프로젝트 수 예측 모델: 3년 전부터 전날까지의 ‘라이브 프로젝트 수’ 데이터로 학습하여, 미래 1년의 라이브 프로젝트 수를 예측하는 모델입니다. 이 모델의 출력값은 펀딩 금액 예측 모델의 입력값이 됩니다.
- 펀딩 금액 예측 모델: 지지서명 예측값과 라이브 프로젝트 수 예측값을 입력받아 펀딩 금액 예측을 수행합니다. 최종 예측값은 내부의 Elastic Search와 Wadiz DB에 저장합니다.
- ES에 저장된 결과는 Grafana를 통해 아래 그림과 같은 대시보드로 구성하여 결과를 서빙합니다.
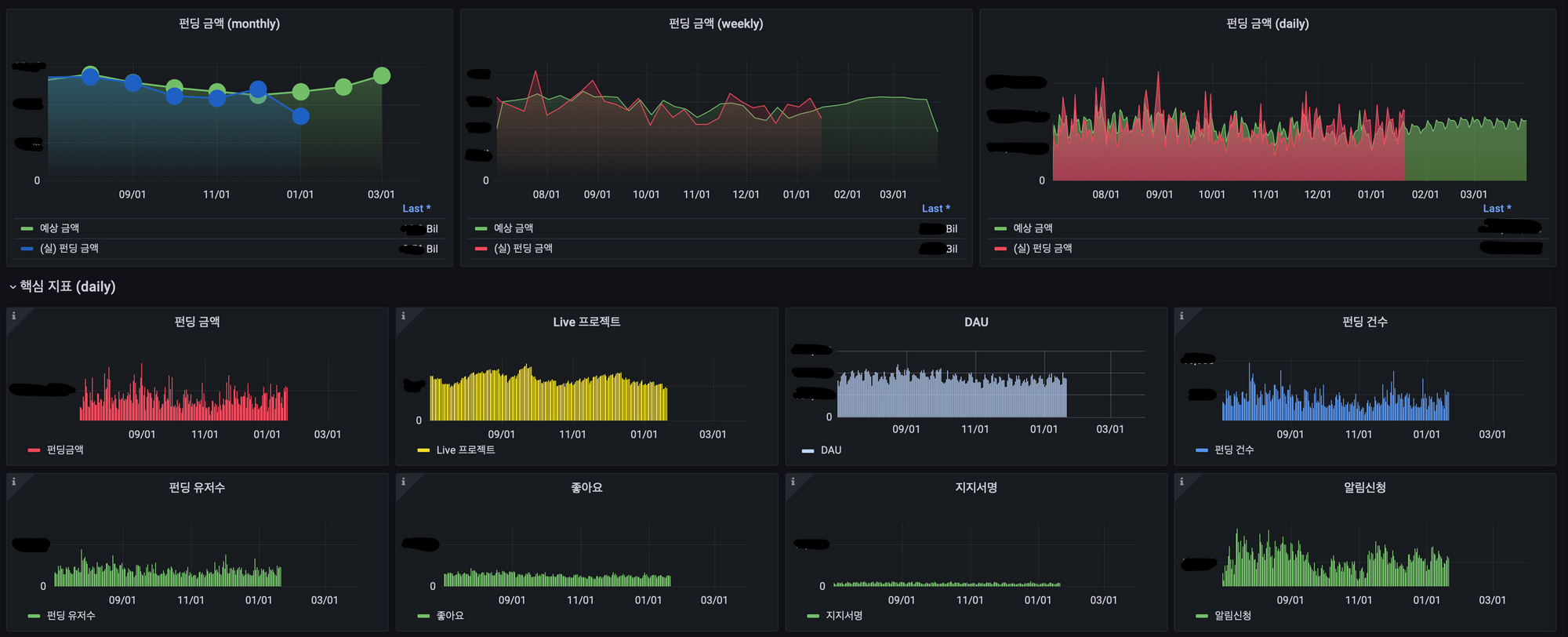
Grafana 월간 펀딩 금액 예측 대시보드
위 대시보드에 월간 펀딩 금액을 비롯하여 주간, 일간 펀딩 금액을 모델의 예측 결과로 aggregation 하여 게시하고 있습니다. 또한 실제 핵심 지표인 펀딩 금액, 라이브 프로젝트 수 등 8개 지표를 함께 구성하여서 한 눈에 와디즈의 주요 지표를 확인할 수 있어요.
지금까지 와디즈에서 전체 펀딩 금액을 예측하기 위해 도입한 ‘Prophet’과 이를 이용한, 학습시키기 위해 진행했던 분석/학습 및 배치 등 전반적인 과정에 대해서 간략히 소개했는데요.
현재 월간 펀딩 예측 모델의 예측값은 위에서 소개한 대시보드를 통해 언제든지 접근할 수 있습니다. 따라서 전사에서 유용하게 활용하고 있지요.
도입부에서 설명한 것처럼 Prophet은 시계열 데이터 분석 전문가나 통계 전문가의 도움이 없는 환경에서도, 편리한 시각화를 통해 빠르고 효율적으로 모델을 만들 수 있음을 보여주었어요. 성능 또한 파라미터와 다른 Feature를 조합하여 효과적으로 향상할 수 있음을 확인했습니다.
Prophet은 시계열 데이터 자체의 트렌트, 패턴을 찾는데 적합한 툴이며 Outlier에 강건하다고 알려져 있습니다. 하지만 주식과 같이 패턴이 일정하지 않거나 외부 이벤트에 의해 큰 영향을 받는 시계열 데이터에 대해서는 예측이 잘 동작하지 않을 수 있다는 점을 주의해야 해요. 이 점을 상기하면서 Prophet을 가볍게 사용해보시기를 권합니다.
마지막으로 우리는 와디즈의 데이터를 이용하여 함께 메이커와 서포터에게 도움을 줄 수 있는 머신러닝 시스템을 함께 구축하실 분을 찾고 있습니다!
시계열 데이터 모델링을 비롯하여 추천 시스템과 자연어처리 등 다양한 분야를 경험하면서 좋은 동료들과 함께 커리어를 쌓기를 원하시는 분들은 주저 말고 지원해주세요 😉




