
Hello. This is the Wadiz Member Development Team.
Last year, as part of our major redesign, we launched "Feed," an in-app social community. In the first half of this year, we updated and improved this service, renaming it "Friends."
We undertook various tasks to recommend meaningful friends to users. In the process, we utilized a graph database (hereinafter referred to as "graph DB"). Here is an overview of our implementation process.

Development Background
The feedback we received regarding improvements to the "Friends" service was as follows.
- "A friend of a friend I follow"friend of a friend’ that I follow.
- The search results should exclude people you already follow or have blocked.
- ‘‘Friend of a Friend’’ must specify how many friends each one has following them and identify one representative friend.
- ‘‘Friends of friends’ and the number of friends we both follow.

What it will look like once the requirements are implemented
Why a Graph Database?
If we look solely at the requirements, even in RDBs (Relational Databases, hereinafter RDBs)—which we use frequently—it’s not difficult to solve the problem with queries, despite the complexity. But we chose a graph database. Why?
The performance we expect from a service depends on various factors, such as which database we use, how we configure the infrastructure, how we tune the database settings, how we design the model, and the format of the queries sent to the service. Therefore, to build a high-performance service, we must carefully consider the design of each stage and make wise choices regarding which products to use. However, if the expected data structure is clear, we can make specific decisions starting from the database selection.
When searching for "friends of friends," the data must be queried based on "relationships" rather than through simple lookups.
*There is a subtle difference between “relational” and the “relations” we will discuss later in the context of graph databases. The term “relational” in this context derives from the mathematical concept of “relational algebra,” which forms the foundation of RDBMS architecture. Therefore, the term “relational” is interpreted differently from its general meaning.
Since we need to be able to query data in greater detail based on "relationships," there are limitations to using only an RDB, which relies on column-based foreign keys. Given that the redesign requirements allow for "relationship"-based modeling, we believed that a graph database—whose architecture is specifically designed for "relationships"—would enable us to design a more stable service.
To explain why graph databases are well-suited for "relationships," I’ll describe the difference in how developers and non-developers perceive graphs.

(Left) General graph / (Right) The Bridges of Königsberg (Source: Leonhard Euler, *Solutio Problematis ad Geometriam Situs Pertinentis*)
* The Bridges of Königsberg: The bridges for which Euler proved the "one-stroke" problem by abstracting a graph from a map of the town.
Let’s look at the graphs we’re familiar with. If data is represented by points and lines defined by specific values, we can call it a graph. From a developer’s perspective, if we can identify various paths and abstract them from the relationships between the graph’s nodes, then all such structures can be called graphs. Their shape resembles the bridges of Königsberg.
If the data to be handled in a graph database can be represented as nodes and edges, and meaningful insights can be derived from those relationships, then it is considered suitable for a graph database. When applied to a social networking service, for example, users—including friends—can be represented as nodes, and follow relationships (including their direction) as edges to abstract the data into a graph. A graph database can be described as a database designed to facilitate the modeling and querying of graph data.
The Process of Selecting a Graph Database
Graph databases may seem unfamiliar at first glance, but there are actually quite a few products available. We chose Neo4j.
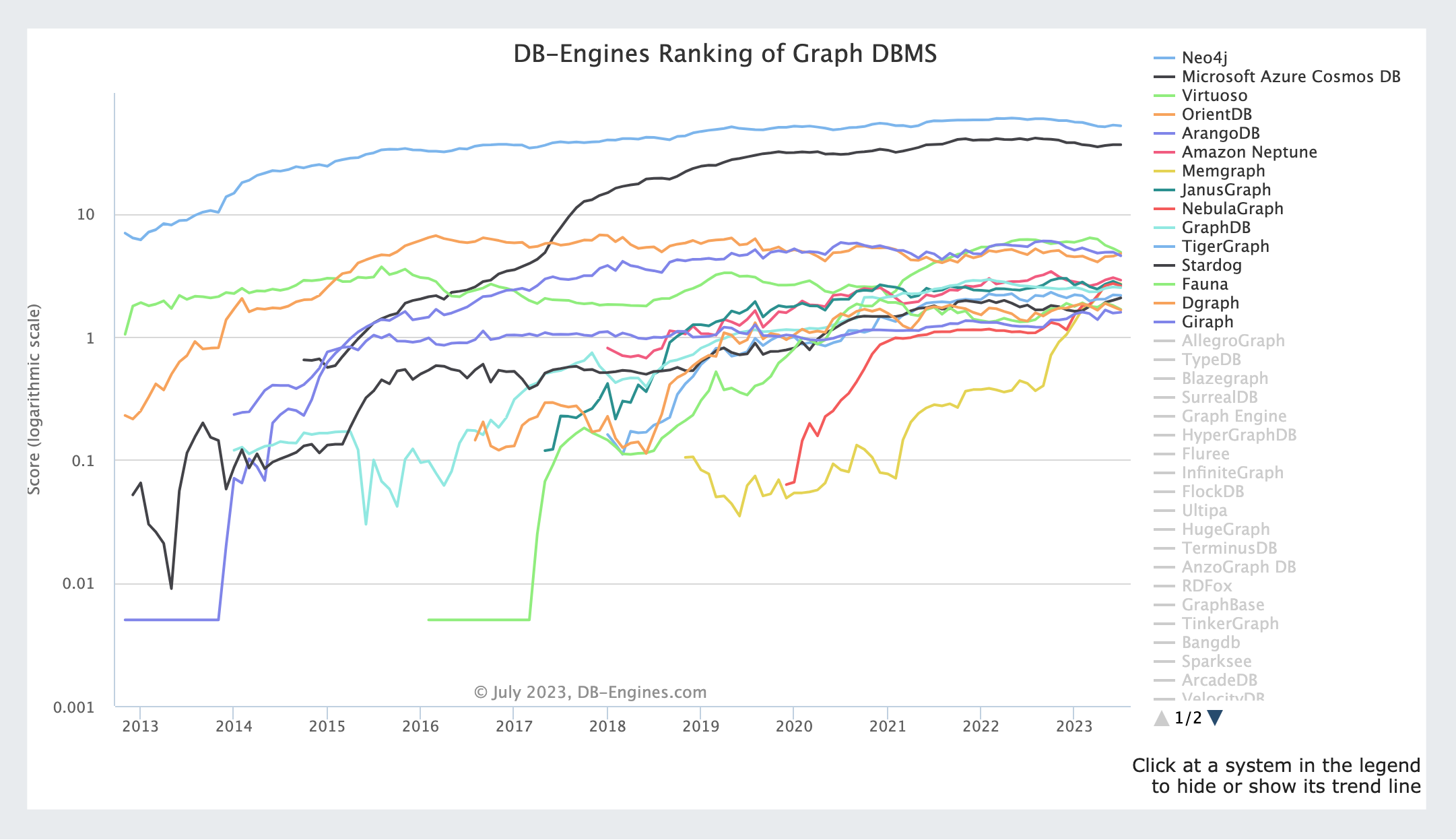
Currently the #1 ranked product! Not that the ranking necessarily means the product is outstanding, though 😅 / DB-Engines Ranking of Graph DBMS
We reviewed the products based on the criteria below.
- Is this a reliable product?
- Are there many references?
- Is it easily accessible?
- Is the learning curve reasonable?
- Is the price reasonable?
- Is it easy to expand the infrastructure?
I was able to get a pretty good sense of the differences between positions 1 through 3 just by looking at the ranking above. The ranking is largely based on popularity. The high rankings indicate that these products are widely used and that people are actively interested in them. I felt that this meant they offered a high degree of reliability, had plenty of references, and were easily accessible.
I figured that the learning curve would be the same regardless of which graph database I chose (4), and since Neo4j offers a Community edition, I thought it might be a good option depending on the architecture and circumstances (5).
In terms of infrastructure scalability, cloud-based products like Microsoft Cosmos DB and AWS Neptune also seemed like good options. However, since Neo4j also offers cloud-based products and its enterprise version supports clustering, we determined that Neo4j was the best fit.
Development Process
Neo4j Desktop
Neo4j offers a tool called "Neo4j Desktop."

Neo4j Desktop after installation and launch; installation path: Download Neo4j Desktop
Neo4j Desktop makes it easy to install and test Neo4j in a local environment. It also offers remote access to Neo4j instances running on actual servers, allowing you to test in an environment identical to your local setup. Additionally, it displays query results as graphs, making it ideal for visualizing graph data.

You can view the data in graph form.
Just as RDBs have SQL (Structured Query Language), graph databases have GQL* (Graph Query Language).
*This may be confused with GraphQL during searches. The same abbreviation, GQL, is used for both.
Among the various GQLs, Neo4j uses "Cypher." Although Neo4j created and released it, it has since been known as "openCypher,’ and is now supported by various vendors.
Let me briefly explain the basic syntax. Cypher creates and manages data using nodes and relationships*. The main features are as follows.
*While graph algorithms typically use the terms "vertex" and "edge," Cypher uses "node" and "relationship."
- NodeNodes are distinguished by attaching "Labels," and each Node instance stores data by adding "Properties."
- RelationshipA 'Relationship' has a 'Type', which is distinct from a 'Label', and can have only a single 'Type'. (In the case of a 'Label', a single Nodecan have multiple ‘Labels’.)
- Relationshipalso stores data by adding a 'Property'.
- Since Neo4j is a schema-free NoSQL database, there are few restrictions on "properties." (Properties can be added dynamically, and there are no restrictions on the data types of individual properties.)

Let me give you a simple example of a query. Here is the query and its results.
Create a Node
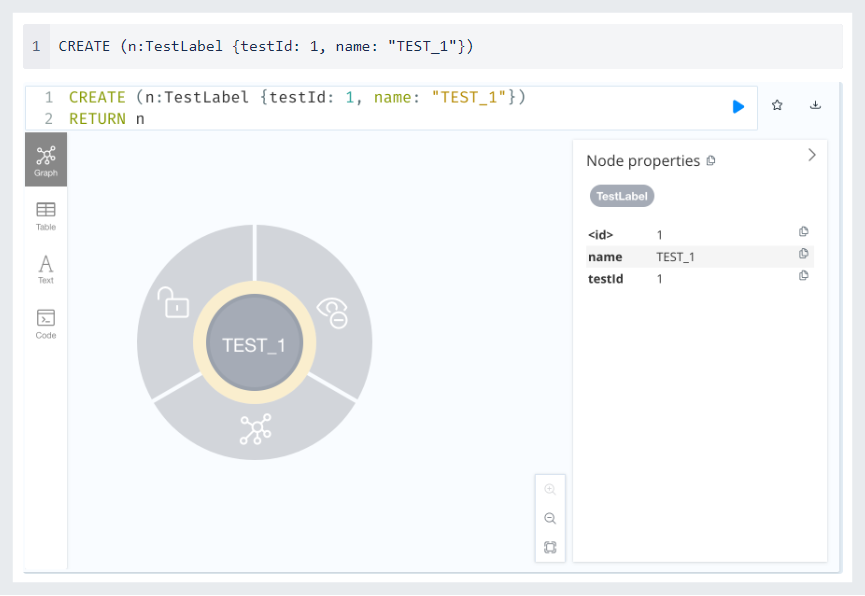
Create Relationship

Views
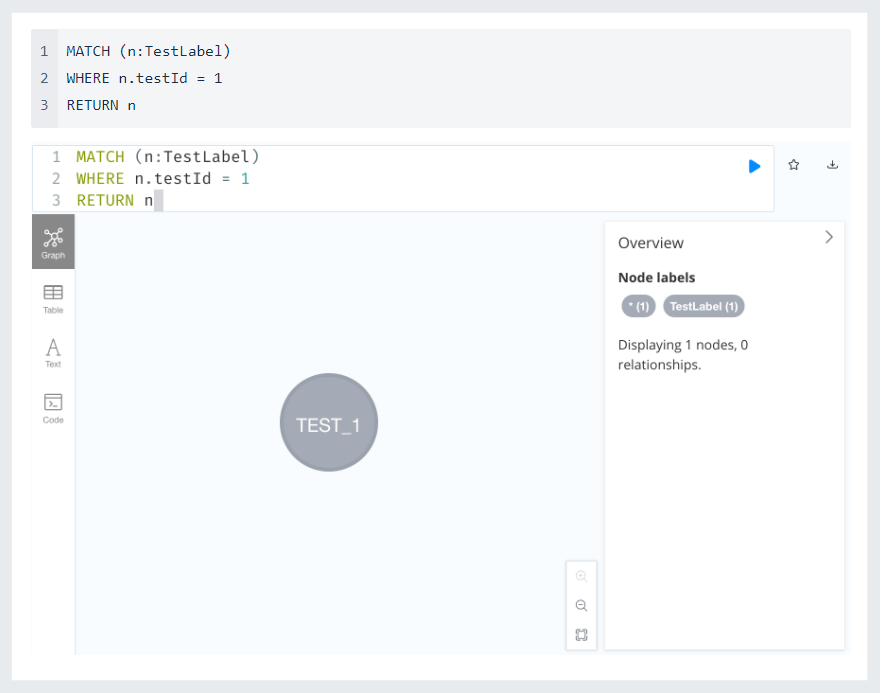
Update

Delete: Normal Delete

Delete: Delete including relationships

Graph Data Modeling
The actual development is carried out by testing with Cypher in Neo4j Desktop. The most important part of the development process using a graph database is modeling.
Data becomes more useful when it is represented in graph form. To achieve optimal performance when querying a graph database, the data must first be modeled to reflect graph patterns. That is why graph data modeling is one of the most important tasks.
Let me give you an example of modeling. Suppose we are modeling a transaction in which Person A transferred $100 to Person B via "Wadiz" on "July 9, 2023, at 2:00 PM."
CREATE (a1:Account {name: 'A'})-[:TRANSFER {
id: 555,
amount: 100,
currency: 'USD',
bank: 'Wadiz',
date_time: '2023-07-09 14:00:00'
}]->(a2:Account {name: 'B'})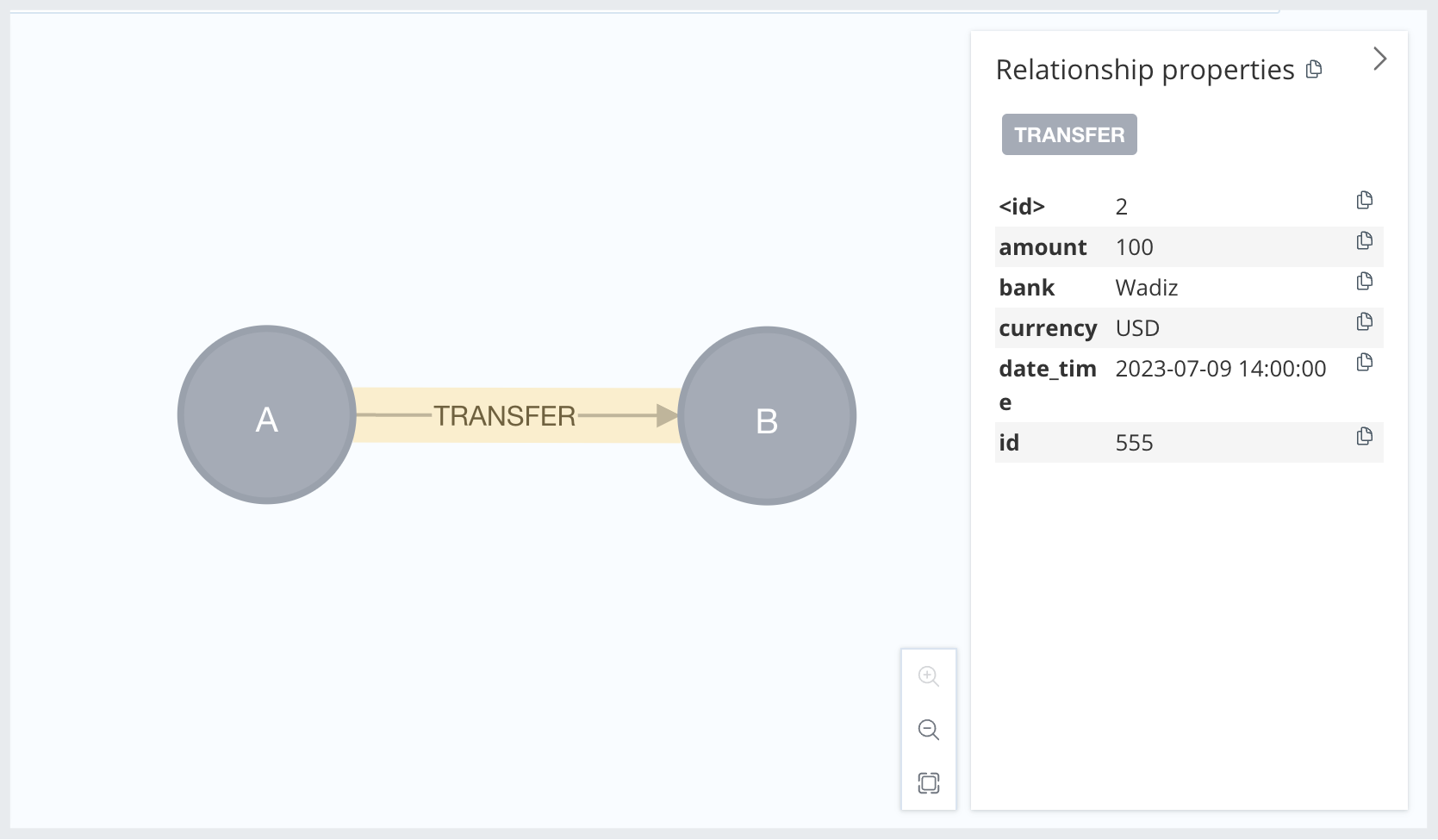
It’s a very intuitive model. What do you think? It might seem a bit unfamiliar, but I don’t think it’s wrong. David Allen, one of the architects at Neo4j, said of this modeling, ‘'Very bad." Why do you think he feels that way? Let’s take a look at another model.
CREATE (bk:Bank { name: "Wadiz" })
CREATE (c:Currency { name: "USD" })
CREATE (a:Account {name: 'A'})-[:INITIATES]->
(bt:BankTransfer { id: 555, amount: 100, date_time: '2023-07-09 14:00:00' })
-[:RECEIVES]->(b:Account {name: 'B'})
CREATE (b)-[:ORIGIN_BANK]->(bk)
CREATE (b)-[:CURRENCY]->(c)
How does this compare to the first model? Does it look more complex and difficult? David Allen describes the model above as ‘Much better.”
The first model is similar to an RDB model. It looks like a diagram showing the relationships between rows in the ‘Account’ table and the ‘Transfer’ table, which maps the relationships between ‘Account’ entries.
In the second modeling approach, we separate the data within the dataset and break down the "relationships" between each piece of data, thereby enabling relationship-based data scalability and representing various relationships.
Since the foundation for finding data within a graph ultimately lies in "relationships," this type of modeling provides the basis for performing a wide variety of queries. (Relying solely on query tuning based on a deep understanding of Cypher has its limits when it comes to maximizing performance. Fundamentally, if the modeling does not provide the foundation for performance, it is difficult to write effective queries and expect high performance.)
As a result, I had to devote a great deal of effort to modeling during the actual work. After setting up the data pipeline based on the original RDB, I modeled the graph database and wrote and tested queries based on that model. (I have much more to say about modeling, but I recommend reading the article by David Allen.)
SQL vs. Cypher
Let’s go back to the beginning and rethink the requirements. I’ll write SQL queries based on the current RDB and compare them with Cypher queries in terms of query content and performance.
*Although the environments aren’t exactly identical, the 8-core, 16GB configuration is the same. We’ll compare only the initial load execution time without using `LIMIT`.
<테스트 대상의 데이터>
- Number of "friends": Approximately 1,300
- Number of "friends of friends": 8,000 (including duplicates: 120,000)
SQL
* For clarity, the table and column names have been replaced with placeholder text.
SELECT *
# '친구의 친구'와 공통 팔로워 수
,(SELECT count(f1.<팔로워_USER_ID>) as cnt
FROM [팔로우_테이블] f1
INNER JOIN [팔로우_테이블] fx ON (f1.<팔로우_타겟_USER_ID> = fx.<팔로우_타겟_USER_ID> AND fx.<팔로우_여부> is true)
INNER JOIN [USER 테이블] u on u.<USER_ID> = f1.<팔로우_타겟_USER_ID>
WHERE f1.<팔로워_USER_ID> = <##조회_대상_USER##>
AND fx.<팔로워_USER_ID> = follow_of_follow.fx
AND f1.<팔로우_여부> is true
) AS common_follow_count
FROM (SELECT GROUP_CONCAT('(', f1.<팔로우_타겟_USER_ID>, ',', u1.<USER_NAME>, ')') as f1_list, f1.<팔로우_타겟_USER_ID> as rep_f1_user_id, u1.<USER_NAME> as rep_f1_user_name,
count(f1.<팔로우_타겟_USER_ID>) as f1_count, fx.<팔로우_타겟_USER_ID> as fx, u2.<USER_NAME> as fx_name
# 1차 팔로우 조건: 팔로우가 ON된 정상 User
FROM (SELECT <팔로워_USER_ID>, <팔로우_타겟_USER_ID>, <팔로우_여부> FROM [팔로우_테이블] f
INNER JOIN [USER 테이블] u on u.<USER_ID> = f.<팔로우_타겟_USER_ID>이
WHERE <팔로워_USER_ID> = <##조회_대상_USER##> AND <팔로우_여부> is true) f1
# '친구', '친구의 친구' User 정보 Join
INNER JOIN [팔로우_테이블] fx ON fx.<팔로워_USER_ID> = f1.<팔로우_타겟_USER_ID> AND f1.<팔로우_여부> is true AND fx.<팔로우_여부> is true
INNER JOIN [USER 테이블] u1 ON f1.<팔로우_타겟_USER_ID> = u1.<USER_ID>
INNER JOIN [USER 테이블] u2 ON fx.<팔로우_타겟_USER_ID> = u2.<USER_ID>
# '친구의 친구' 중 조회자 제외, 이미 '친구'인 경우 제외, 차단한 경우 제외
WHERE fx.<팔로우_타겟_USER_ID> != <##조회_대상_USER##>
AND fx.<팔로우_타겟_USER_ID> NOT IN (SELECT <팔로워_USER_ID> FROM [팔로우_테이블] WHERE <팔로워_USER_ID> = <##조회_대상_USER##> AND <팔로우_여부> is true)
AND fx.<팔로우_타겟_USER_ID> NOT IN (SELECT <차단_USER> FROM [차단_테이블] WHERE <USER_ID> = <##조회_대상_USER##> AND <팔로우_여부> is true)
GROUP BY fx.<팔로우_타겟_USER_ID>
) follow_of_follow
// '친구'가 많이 팔로우 하는 순으로 정렬
ORDER BY follow_of_follow.f1_count DESCCypher
CALL {
// '친구의 친구' 조회
MATCH (n:User {user_id: <##조회_대상_USER_ID##>})-[r1:FOLLOW]->(f1:User)-[r2:FOLLOW]->(fx:User)
// 이미 '친구' User, 차단한 User, 조회 당사자 제외
WHERE NOT ((n)-[:FOLLOW]->(fx)) AND NOT ((n)-[:BLOCK]->(fx)) AND n <> fx
// '친구의 친구' 정보
RETURN n, fx, fx.user_id as target_id, fx.user_name as target_name,
count(fx.user_Id) as target_count, collect(distinct f1) as f1_list
// '친구'가 많이 팔로우 하는 순으로 정렬
ORDER BY target_count DESC
}
CALL {
// '친구의 친구'와 공통 팔로워 수
WITH n, fx
MATCH (n)-[:FOLLOW]->(c:User)<-[:FOLLOW]-(fx)
RETURN count(c) as common_follow_count
}
WITH target_id, target_name, target_count, f1_list, common_follow_count
// '친구의 친구'의 기본 정보
RETURN target_id, target_name, target_count,
// '친구의 친구'를 찾는데 사용된 '친구' 기본 정보
f1_list[0].user_id as weight_rep_user_id, f1_list[0].user_name as weight_rep_username, size(f1_list) as weight_count,
// '친구의 친구'와 공통 팔로워 수
common_follow_countResults
<첫 실행 시간>
- SQL: 37.73 seconds
- Cypher: 2.27 seconds
First, let’s take a look at the queries. What do you think? Which query is more readable? Even if you’re not familiar with Cypher, anyone can see that the Cypher query is more readable and easier to understand.
How does it perform? Of course, since both use an internal cache, there aren’t any major issues after the initial run. However, since that cache becomes virtually useless once the query target changes, it’s clear that querying graph-pattern data in an RDB is very risky.
Even with Cypher, it’s impossible to completely avoid some latency when dealing with large volumes of data. In actual production environments, we employ various strategies to manage this.
Service Coverage
What's new with the 'Friends' service?
The "Friends" service presents "friends of friends" under the name "Supporters I Might Know." It also displays content from "recently active friends." This is also handled using a graph database. The “recently active friends” feature has more demanding requirements than “friends of friends.” The details are as follows.
- We are currently identifying users to recommend based on various activities, such as "endorsement signatures," "experience reviews," and "satisfaction reviews," conducted within a specific time period.
- Among these users, we first look for "friends of friends."
- Find "Friends who follow me" among those users.
- In addition, we recommend users in various ways.
- The user and any users with whom the user has a negative relationship must be excluded.
This project required the use of much more data than the "friend of a friend" approach. Modeling was a more critical and key requirement. We had to design a more strategic modeling approach, and I’ll be sure to share more about that with you if the opportunity arises.
Using a graph database, the "Friends" service initially applied the "friends of friends" concept to recommend "friends" with whom I have close relationships Wadiz. Later, through the "Recently Active Friends" feature, I was able to receive the latest updates from a variety of "friends" who are meaningful to me.

Service Monitoring Over the Past Month

Purple line: Friend of a friend; Blue line: Friend who has been active recently
This is the average response latency recorded over the past month. On average, performance remains within 100 ms. Even though this API handles relational data based on a large volume of information, it was able to respond quickly without any slowdown.
In closing
Adopting new technology is always a challenge. However, I believe it’s difficult to ride the wave of rapid change without taking risks and putting things into practice.
During the implementation of the graph database, the Wadiz Member Development Team didn’t just rely on the graph database alone. We applied various new technologies Wadizis exploring and integrated them into our live services. I believe this marks a significant milestone for the new services we’ll be developing in the future.
This achievement wasn’t something I accomplished on my own. I was able to bring this project to a successful conclusion thanks to the many colleagues who worked with me every step of the way, from design to implementation. With colleagues like you—who truly support one another—I’m already looking forward to our next challenge. Thank you 🙂
Want to join us? 👀
View our current developer job openings 👉 Click here




